OLAP (clickhouse)
行存储利于数据一行一行写入,适合 OLTP 系统;列存储利于对列的操作和数据聚合统计,适合 OLAP 系统。
列式存储
传统行存储:
| Row | WatchID | JavaEnable | Title | GoodEvent | EventTime |
|---|---|---|---|---|---|
| #0 | 89354350662 | 1 | Investor Relations | 1 | 2016-05-18 05:19:20 |
| #1 | 90329509958 | 0 | Contact us | 1 | 2016-05-18 08:10:20 |
| #2 | 89953706054 | 1 | Mission | 1 | 2016-05-18 07:38:00 |
| #N | … | … | … | … | … |
列式存储:
| Row: | #0 | #1 | #2 | #N | EventTime |
|---|---|---|---|---|---|
| WatchID: | 89354350662 | 90329509958 | 89953706054 | … | 2016-05-18 05:19:20 |
| JavaEnable: | 1 | 0 | 1 | … | 2016-05-18 08:10:20 |
| Title: | Investor Relations | Contact us | Mission | … | 2016-05-18 07:38:00 |
| GoodEvent: | 1 | 1 | 1 | … | … |
| EventTime: | 2016-05-18 05:19:20 | 2016-05-18 08:10:20 | 2016-05-18 07:38:00 | … | … |
优势
基于列模式的存储,天然就会具备以下几个优点:
自动索引
因为基于列存储,所以每一列本身就相当于索引。所以在做一些需要索引的操作时,就不需要额外的数据结构来为此列创建合适的索引。
利于数据压缩
利于压缩有两个原因。一来大部分列数据基数其实是重复的,拿上面的数据来说,同一个 author 会发表多篇博客,所以 author 列出现的所有值的基数肯定是小于博客数量的,因此在 author 列的存储上其实是不需要存储博客数量这么大的数据量的;二来相同的列数据类型一致,这样利于数据结构填充的优化和压缩,而且对于数字列这种数据类型可以采取更多有利的算法去压缩存储。
OLTP & OLAP
OLTP(联机事务处理)和 OLAP(联机分析处理)是两种不同的数据处理系统,分别用于处理日常事务和数据分析。
OLTP - 联机事务处理
OLTP 系统主要用于管理和处理日常业务操作中的大量短小在线事务,如订单输入、库存管理、银行交易等。这些系统强调高并发性、快速响应时间和数据完整性,以确保事务的可靠性和一致性。
- 高并发性
- 数据完整性
- 实时性
主要应用于:银行系统的交易处理、在线零售平台订单处理、航班预订系统的座位分配(都是对并发性和实时性要求较高的场景)
OLAP - 联机分析处理
OLAP 系统主要用于支持复杂的查询和分析操作,帮助企业进行决策支持。它们从多个角度、多维度地分析大量历史数据,以发现潜在的模式和趋势。
- 多维度分析:允许用户从不同角度查看和分析数据,例如按时间、地区、产品等维度。
- 复杂查询:支持复杂的聚合和计算操作,如汇总、平均值、最大值等。
- 数据整合:通常从多个来源收集数据,进行清洗和整合,以提供全面的分析视图。
主要应用于:市场营销分析、财务报表分析、业务流程管理和绩效评估(侧重于数据分析和决策支持)
一些关键特征:(来源于 clickhouse)
- 绝大多数是读请求
- 数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
- 已添加到数据库的数据不能修改。
- 对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
- 宽表,即每个表包含着大量的列
- 查询相对较少(通常每台服务器每秒查询数百次或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每个查询有一个大表。除了他以外,其他的都很小。
- 查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
ClickHouse 示例
创建一个表并插入一个大型数据集(包含两百万行的 纽约出租车数据)。然后,对数据集执行查询,包括如何创建字典并使用它执行 JOIN。
数据插入查询
创建新表
1
2
3
4
5
6
7
8
9
10
11CREATE TABLE trips
(
`trip_id` UInt32,
`vendor_id` Enum8('1' = 1, '2' = 2, '3' = 3, '4' = 4, 'CMT' = 5, 'VTS' = 6, 'DDS' = 7, 'B02512' = 10, 'B02598' = 11, 'B02617' = 12, 'B02682' = 13, 'B02764' = 14, '' = 15),
`pickup_date` Date,
`pickup_datetime` DateTime,
···
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(pickup_date)
ORDER BY pickup_datetime;插入数据集:从远端的 CSV 文件中下载数据
1
2
3
4
5
6
7
8
9
10INSERT INTO trips
SELECT * FROM s3(
'<https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_{1..2}.gz>',
'TabSeparatedWithNames', "
`trip_id` UInt32,
`vendor_id` Enum8('1' = 1, '2' = 2, '3' = 3, '4' = 4, 'CMT' = 5, 'VTS' = 6, 'DDS' = 7, 'B02512' = 10, 'B02598' = 11, 'B02617' = 12, 'B02682' = 13, 'B02764' = 14, '' = 15),
`pickup_date` Date,
`pickup_datetime` DateTime
···
") SETTINGS input_format_try_infer_datetimes = 0插入完成后,验证是否成功
1
SELECT count() FROM trips
简单分析数据,就是写 SQL,但是效率特别快。
1
2
3
4
5SELECT
passenger_count,
ceil(avg(total_amount),2) AS average_total_amount
FROM trips
GROUP BY passenger_count
ES
ElasticSearch 是一个开源的分布式 RESTful 搜索和分析引擎、可扩展的数据存储和向量数据库,能够解决不断涌现出的各种用例。作为 Elastic Stack 的核心,它会集中存储您的数据,让您飞快完成搜索,微调相关性,进行强大的分析,并轻松缩放规模。可以用来实现搜索、日志统计、分析、系统监控等功能。
企业应用定位:采用 Restful API 标准的可扩展和高可用的实时数据分析的全文搜索工具。
Elastic Stack(ELK)
- 是以 ElasticSearch 为核心的技术栈,包括 Beats、Logstash、kibana、ElasticSearch
- Elastic Search 是 ELK 的核心,负责存储、搜索、分析数据
- kibana 负责数据可视化
- Logstash、Beats 负责数据抓取
倒排索引
ElasticSearch 底层是基于 Lucene 来实现的。Lucene 是一个 java 语言的搜索引擎类库,是Apache 公司的顶级项目。优势是**易扩展、高性能(基于倒排索引)**。
倒排索引的概念是基于MySQL这样的正向索引而言的。Mysql 给表中每行数据的 id 添加索引,这样查询的时候直接走索引去查询。效率会大大提高。但是如果是基于其中一个字段如(title)做模糊查询,根据索引只能逐行扫描,然后把符合条件的筛选出来。事实上也是全表扫描,随着数据量增加,其查询效率也会越来越低。
倒排索引中有两个非常重要的概念:
文档(
Document):用来搜索的数据(如上面说的 title),其中的每一条数据就是一个文档。例如一个网页、一个商品信息。文档和字段:
ElasticSearch 是面向文档(Document)**存储的,可以是**数据库中的一条商品数据**,一个订单信息。文档数据会被序列化为 Json 格式后存储在 ElasticSearch 中。而Json文档中往往包含很多的字段(Field),类似于 Mysql 数据库中的列**。
词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条。
创建倒排索引是对正向索引的一种特殊处理,流程如下:
- 将每一个文档的数据利用算法分词,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档 id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如 hash 表结构索引
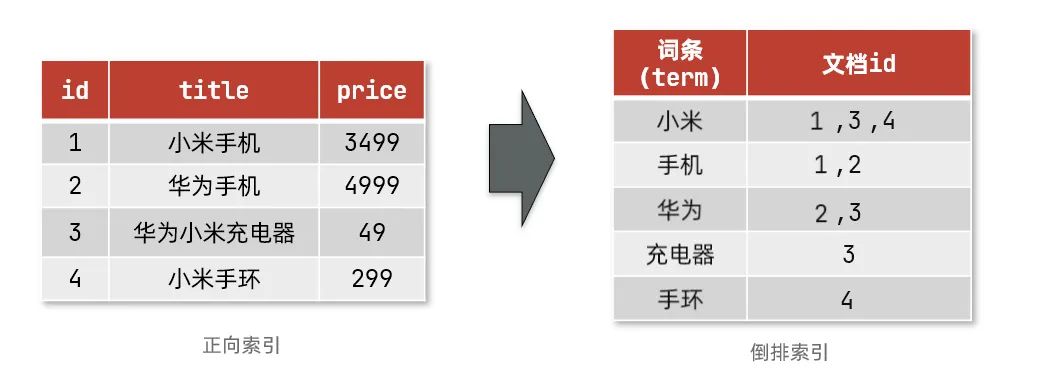
搜索流程如下(以搜索 “华为手机” 为例):
- 用户输入条件
"华为手机"进行搜索 - 对用户输入内容分词,得到词条:
华为、手机 - 拿着词条在倒排索引中查找,可以得到包含词条的文档id:2 3(华为)、1 2(手机),整合去重就是1、2、3
- 拿着文档id到正向索引中查找具体文档
虽然要先查询倒排索引,再查询倒排索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快。无需全表扫描。
Grafana
概念
- Dashboard:相当于一个看板,可以是很多图表的集合,类似概览
- Row:Dashboard 上的一块区域,可以将图表分组展示
- Panel:Dashboard 上具体的一个图表
JOSN Model
Grafana 整个看板内容,包括设置项都是用 JSON 描述的,所以可以直编辑 JSON 格式的字符串。
示例
制作一个 pie chart,基本步骤:
设定变量,如:进行 SQL 查询时需要用到 psm 和 domain 去查询对应的数据
- 在 settings 中找到 Variables,添加数据,type 可以直接选择 textbox 来输入数据进行查询
- 可以可视化操作也可以直接编写 JSON(json model)
写出每一个分支饼的 sql 语句,e.g:
1
2
3
4SELECT
COUNT(IP) AS BAD # 也就是选取其中的 BAD IP 的 count 作为 BAD 这个饼的 value
FROM xxx
WHERE rtype = 'bad' AND psm = '${psm}' AND domain = '${domain}'每个分支都写好之后,选择 Visualization 为 pie chart 或其他饼状图的结构
Hive
Hive 是一个基于 Hadoop 的数据仓库工具,用于查询和管理大规模数据。它的语法类似于 MySQL,但底层运行在 Hadoop 生态系统上,适合处理海量数据。
Hive 与 MySQL 的主要区别
数据存储
:
- MySQL 存储在本地磁盘。
- Hive 存储在 Hadoop 的 HDFS(分布式文件系统)中。
性能
:
- MySQL 适合实时查询。
- Hive 适合离线分析,处理大规模数据。
数据模型
:
- MySQL 主要使用行存储。
- Hive 支持行存储和列存储。
Hive 与 Spark
| Hive | Spark | |
|---|---|---|
| 作用 | 主要用于大数据查询(SQL 引擎) | 主要用于大数据计算(数据处理) |
| 运行方式 | 基于 MapReduce 计算,较慢 | 基于内存计算,速度快 |
| SQL 处理 | 主要依赖 Hadoop HDFS | 可读取 HDFS、Hive、Kafka、S3 等多种数据源 |
| 适用场景 | 适用于批量数据分析 | 适用于流式处理、大规模计算 |
在 Hive 里,执行 SQL 直接通过hive -e "SELECT * FROM table" 就行。
但 Spark 里,我们需要创建一个 SparkSession 来管理 SQL 操作。
e.g:
1 | # 创建 SparkSession |