相关概念
| Zero-shot | 一种无需特定任务的训练数据,直接利用预训练模型进行预测的方法。这种能力主要依赖于模型的预训练阶段所获得的广泛知识和泛化能力。 |
|---|---|
| Few-shot | 利用少量样本进行模型训练或微调,从而使模型能够在特定任务上表现良好。这种方法依赖于给模型提供几个示例,使其能够提高任务理解的情况。 |
| Temperature | 用于调整生成过程的随机性。值越大,生成的文本随机性和创造性越高;值越低,生成的文本更确定和保守。[0,1]。 |
| Top_p | 通过累积概率(又称为“核”)来选择候选 token。模型会从累计概率达到 top_p 值的候选集中采样。值越大,输出的 token 类型越丰富。[0,1]。 |
| Top_k | 模型在每一步生成时,只考虑概率最高的 k 个 token。top_k 越大,考虑的候选 token 越多,生成的多样性越高。设置为 0 表示禁用此参数。 |
Prompt Framework
- Elavis Saravia 总结的框架,一个 prompt 里需包含以下几个元素:
- Instruction(必须): 指令,即你希望模型执行的具体任务。
- Context(选填): 背景信息,或者说是上下文信息,这可以引导模型做出更好的反应。
- Input Data(选填): 输入数据,告知模型需要处理的数据。
- Output Indicator(选填): 输出指示器,告知模型我们要输出的类型或格式。
- Prompt 的形式多种多样,可以采用自然语言描述,也可以借鉴如函数式编程等思想,但通常应至少包含三个要点:
- 角色描述
- 任务描述
- 格式约束
CoT
Chain-of-Thought (CoT), 鼓励 LLM 在给出最终答案之前逐步解释思索的过程,相当于向 agent 提供了一块“黑板”,agent 可以在这块黑板上“打草稿”,从而减轻推理压力。最简单的 CoT 应用范式就是在 prompt 中加入 “Let's think step by step”。添加更具体的 CoT 描述会对 prompt 效果产生更大的帮助。
n-shot-learning
- Zero-shot
- One-shot
- Few-shot
Few-shot leaning: 指大型语言模型从一小群示例中学习新任务或解决新问题的能力
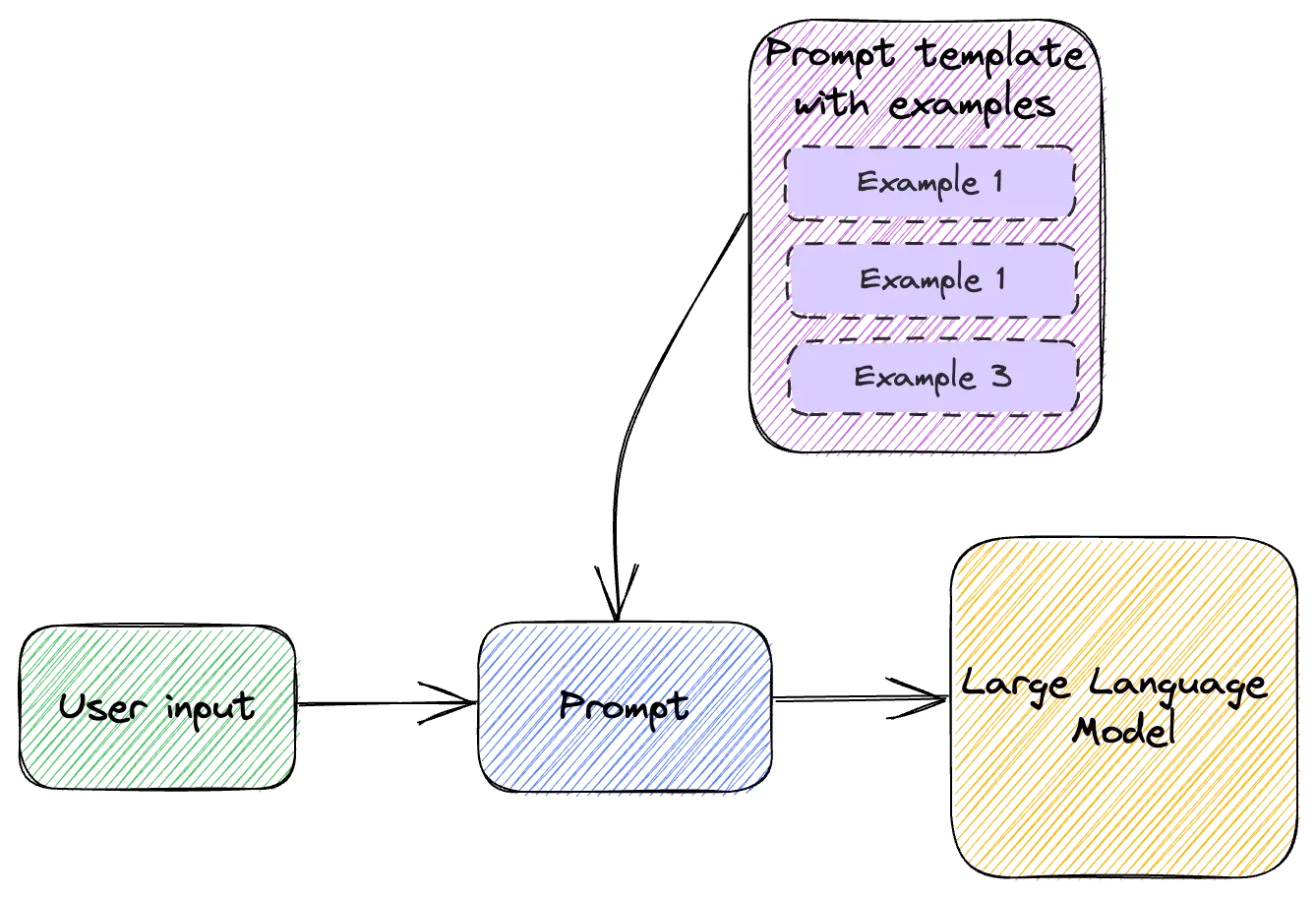
e.g:
1 | chat = ChatTemplate( |
自我一致性
通过少样本 CoT 采样多个不同的推理路径,并使用生成结果选择最一致的答案。这有助于提高 CoT 提示在涉及算术和常识推理的任务中的性能。
1 | Q:林中有15棵树。林业工人今天将在林中种树。完成后,将有21棵树。林业工人今天种了多少棵树? |
输出1:
1 | 当我6岁时,我的妹妹是我的一半年龄,也就是3岁。现在我70岁了,所以她是70-3 = 67岁。答案是67。 |
输出2:
1 | 当叙述者6岁时,他的妹妹是他年龄的一半,也就是3岁。现在叙述者70岁了,他的妹妹应该是70-3 = 67岁。答案是67。 |
输出3:
1 | 当我6岁时,我的妹妹是我的一半年龄,也就是3岁。现在我70岁了,所以她是70/2 = 35岁。答案是35。 |
选取出现频率更高的答案。
prompt chaining
一个重要的提示工程技术是将任务分解为许多子任务。 确定子任务后,将子任务的提示词提供给语言模型,得到的结果作为新的提示词的一部分。 一个任务被分解为多个子任务,根据子任务创建一系列提示操作。
一个比较经典的应用是 coze ···
感觉是 CoT 的升级版,每一个链条都和大模型交互一次,使得每一步的任务单一,准确性提高。
对比:
原来
1
2
3
4
5
6
7你是我们的首席法务官。审查这份SaaS合同的风险,重点关注数据隐私、SLA和责任上限。
<contract>
{{CONTRACT}} {{合同}}
</contract>
然后起草一封给供应商的电子邮件,说明你的担忧和建议修改。链式提示
1
2
3
4
5
6
7你是我们的首席法务官。审查这份SaaS合同的风险,重点关注数据隐私、SLA和责任上限。
<contract>
{{CONTRACT}} {{合同}}
</contract>
在<risks>标签中输出你的发现。1
2
3
4起草一封给SaaS产品供应商的电子邮件,概述以下担忧并提出修改建议。以下是担忧:
<concerns>
{{CONCERNS}} {{关注}}
</concerns>1
2
3
4
5
6你的任务是审查一封电子邮件并提供反馈。这是电子邮件:
<email>
{{EMAIL}} {{电子邮件}}
</email>
就语气、清晰度和专业性给出反馈。
React
ReAct 的灵感来自于 “行为” 和 “推理” 之间的协同作用,正是这种协同作用使得人类能够学习新任务并做出决策或推理。
ReAct 是一个将推理和行为与 LLMs 相结合通用的范例。ReAct 提示 LLMs 为任务生成口头推理轨迹和操作。这使得系统执行动态推理来创建、维护和调整操作计划,同时还支持与外部环境(例如,Wikipedia)的交互,以将额外信息合并到推理中。
第一步是从训练集 (例如 HotPotQA) 中选择案例,并组成 ReAct 格式的轨迹。这些在提示中作为少样本示例。轨迹由多思考-操作-观察步骤组成,如图所示。自由形式的思考用来完成不同的任务,如分解问题、提取信息、执行常识或算术推理、引导搜索公式和合成最终答案。下面是一个 ReAct 提示的示例(摘自论文,为简单起见缩短为一个示例):
1 | 问题 科罗拉多造山带东部区域延伸到的区域的海拔范围是多少? |
Reflection
自我反思将来自环境的反馈(自由形式的语言或者标量)转换为语言反馈,也被称作 self-reflection,为下一轮中 LLM 智能体提供上下文。这有助于智能体快速有效地从之前的错误中学习,进而提升许多高级任务的性能。
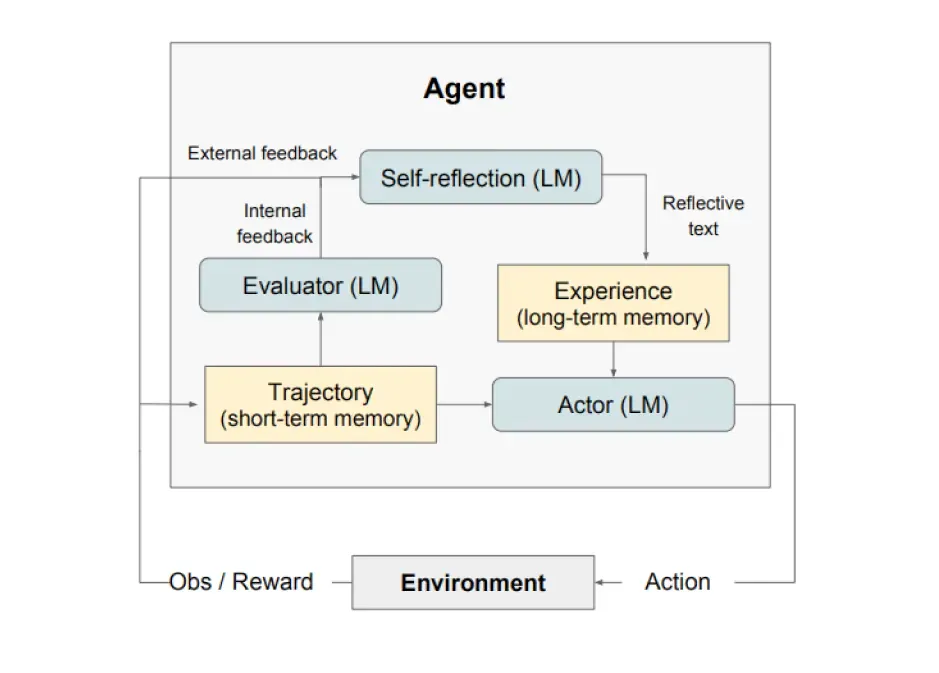
如上图所示,自我反思由三个不同的模型组成:
- 参与者(Actor):根据状态观测量生成文本和动作。参与者在环境中采取行动并接受观察结果,从而形成轨迹。此外,还添加了记忆组件为智能体提供额外的上下文信息。
- 评估者(Evaluator):对参与者的输出进行评价。具体来说,它将生成的轨迹(也被称作短期记忆)作为输入并输出奖励分数。根据人物的不同,使用不同的奖励函数(决策任务使用LLM和基于规则的启发式奖励)。
- 自我反思(Self-Reflection):生成语言强化线索来帮助参与者实现自我完善。这个角色由大语言模型承担,能够为未来的试验提供宝贵的反馈。自我反思模型利用奖励信号、当前轨迹和其持久记忆生成具体且相关的反馈,并存储在记忆组件中。智能体利用这些经验(存储在长期记忆中)来快速改进决策。
总的来说,自我反思的关键步骤是a)定义任务,b)生成轨迹,c)评估,d)执行自我反思,e)生成下一条轨迹。下图展示了自我反思的智能体学习迭代优化其行为来解决决策、编程和推理等各种人物的例子。自我反思(Refelxion)通过引入自我评估、自我反思和记忆组件来拓展 ReAct 框架。
Workflow
Prompt chaining
将单一 prompt 组合起来构成一个 workflow,
Prompt chaining decomposes a task into a sequence of steps, where each LLM call processes the output of the previous one. You can add programmatic checks (see “gate” in the diagram below) on any intermediate steps to ensure that the process is still on track.
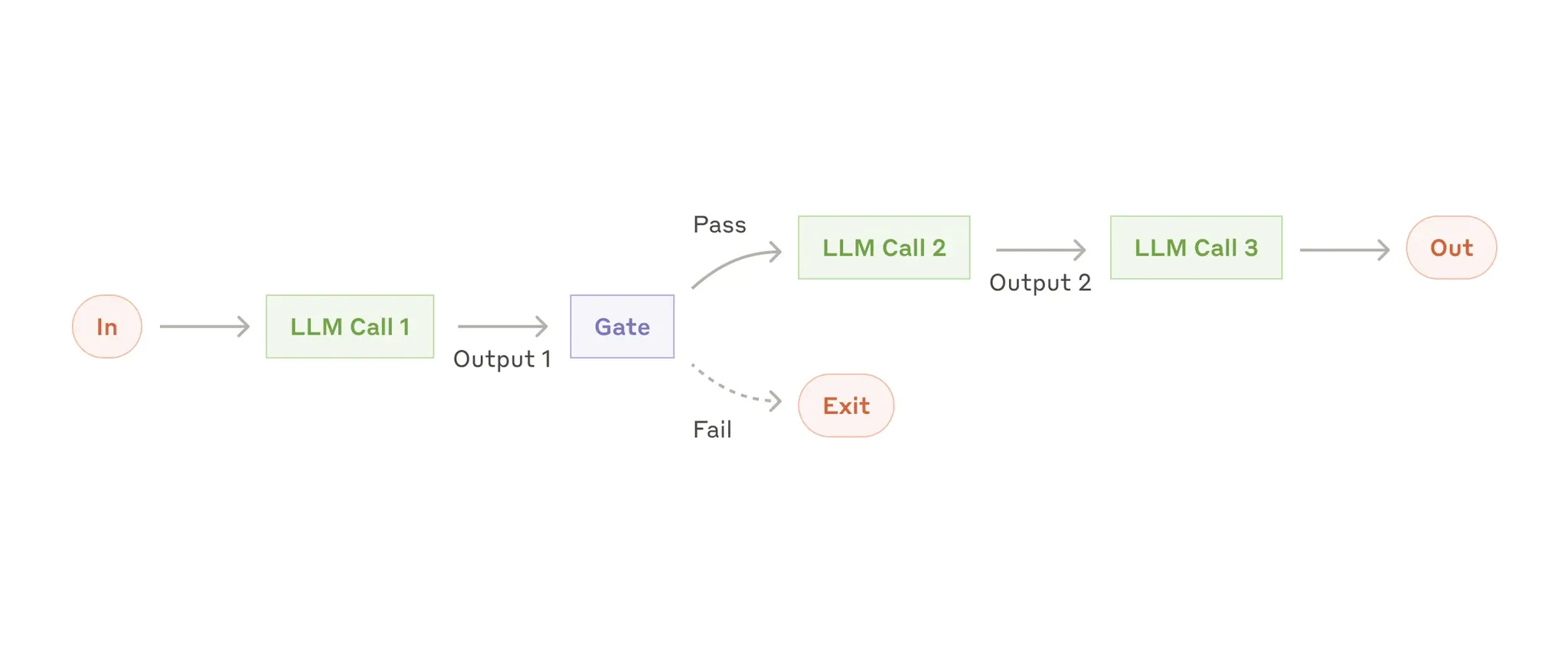
When to use this workflow: 此工作流程非常适合可以轻松、干净地将任务分解为固定子任务的情况。主要目标是通过使每次LLM调用都成为更轻松的任务,在延迟之间进行权衡以获得更高的准确性。
Routing
Routing classifies an input and directs it to a specialized followup task. This workflow allows for separation of concerns, and building more specialized prompts. Without this workflow, optimizing for one kind of input can hurt performance on other inputs.
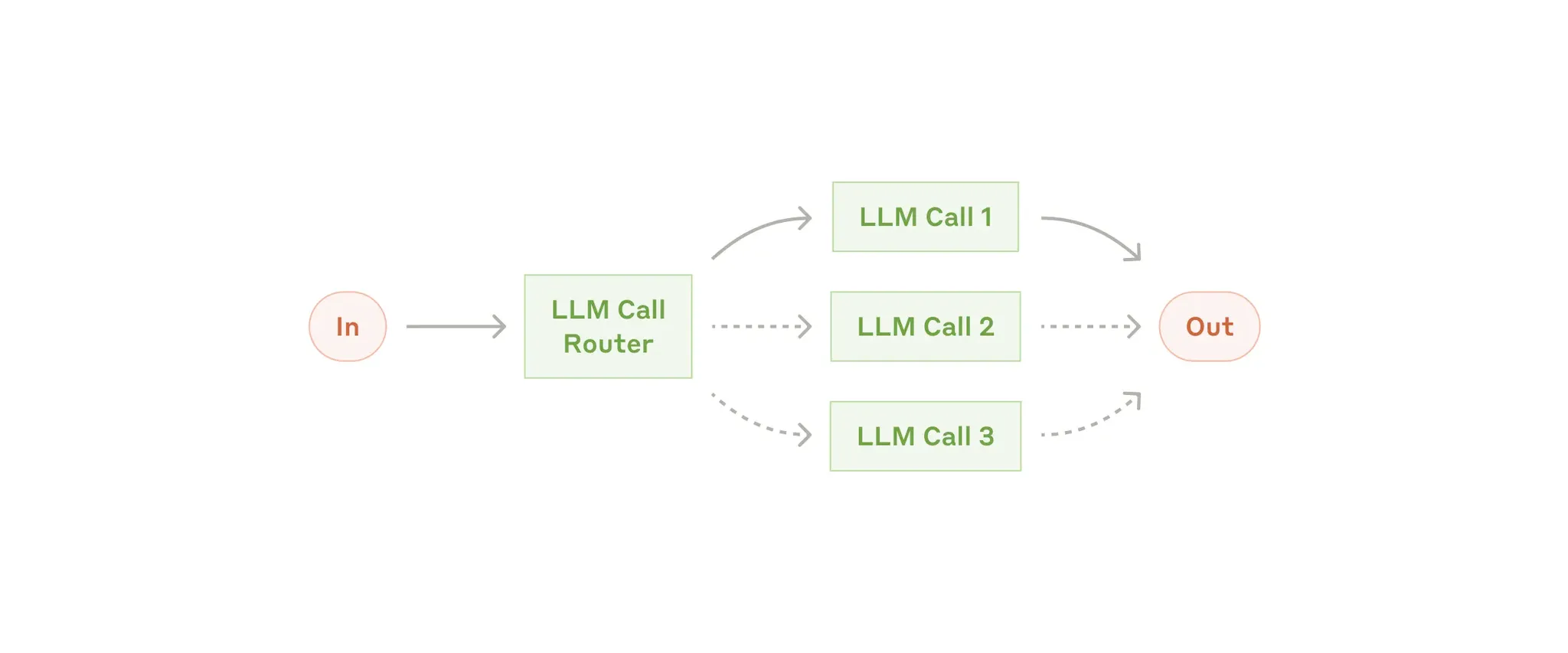
When to use this workflow: Routing 非常适合复杂任务,其中有不同的类别,可以更好地单独处理,并且可以通过LLM或更传统的分类模型/算法准确处理分类。
Parallelization
LLMs can sometimes work simultaneously on a task and have their outputs aggregated programmatically. This workflow, parallelization, manifests in two key variations:
- Sectioning: Breaking a task into independent subtasks run in parallel.
- **Voting:**Running the same task multiple times to get diverse outputs.
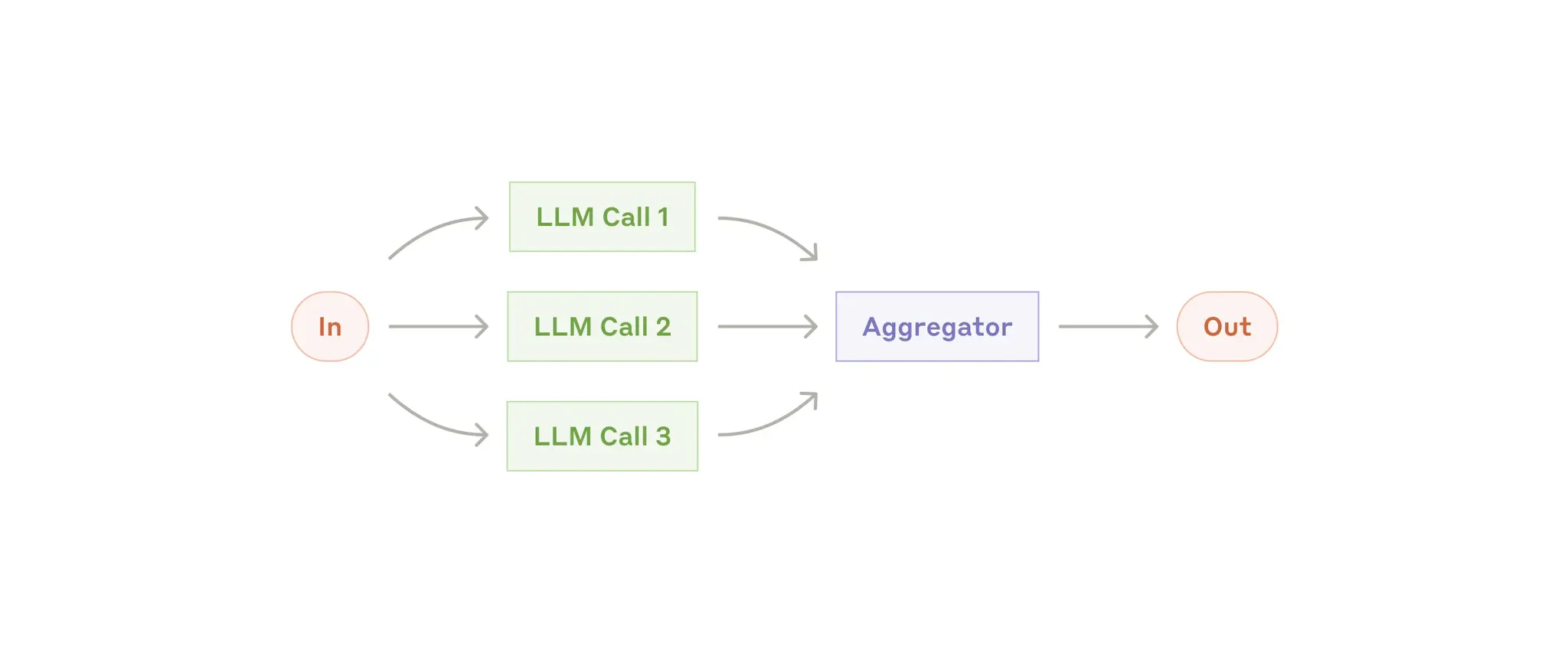
When to use this workflow: 当可以并行化已划分的子任务以提高速度时,或者当需要多个视角或尝试以获得更高的置信度结果时,并行化非常有效。对于具有多个考虑因素的复杂任务,LLMs当每个考虑因素都由单独的LLM调用处理时,通常会表现得更好,从而允许将注意力集中在每个特定方面。